scikit-笔记11:文本分类与垃圾邮件检测
Table of Contents
1 Case Study - Text classification for SMS spam detection
%matplotlib inline import matplotlib.pyplot as plt import numpy as np
We first load the text data from the dataset directory that should be located in
your notebooks directory, which we created by running the fetch_data.py script
from the top level of the GitHub repository.
Furthermore, we perform some simple preprocessing and split the data array into two parts:
- text: A list of lists, where each sublists contains the contents of our emails
y: our SPAM vs HAM labels stored in binary;
- a
1represents a spam message, - a
0represnts a ham (non-spam) message.
import os with open(os.path.join("datasets", "smsspam", "SMSSpamCollection")) as f: lines = [line.strip().split("\t") for line in f.readlines()] text = [x[1] for x in lines] y = [int(x[0] == "spam") for x in lines]
text[:10]['Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat...', 'Ok lar... Joking wif u oni...', "Free entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question(std txt rate)T&C's apply 08452810075over18's", 'U dun say so early hor... U c already then say...', "Nah I don't think he goes to usf, he lives around here though", "FreeMsg Hey there darling it's been 3 week's now and no word back! I'd like some fun you up for it still? Tb ok! XxX std chgs to send, $1.50 to rcv", 'Even my brother is not like to speak with me. They treat me like aids patent.', "As per your request 'Melle Melle (Oru Minnaminunginte Nurungu Vettam)' has been set as your callertune for all Callers. Press *9 to copy your friends Callertune", 'WINNER!! As a valued network customer you have been selected to receivea $900 prize reward! To claim call 09061701461. Claim code KL341. Valid 12 hours only.', 'Had your mobile 11 months or more? U R entitled to Update to the latest colour mobiles with camera for Free! Call The Mobile Update Co FREE on 08002986030']
y[:10][0, 0, 1, 0, 0, 1, 0, 0, 1, 1]
print('Number of ham and spam messages:', np.bincount(y))
type(text)list
type(y)list
- a
Next, we split our dataset into 2 parts, the test and training dataset:
from sklearn.model_selection import train_test_split text_train, text_test, y_train, y_test = train_test_split(text, y, random_state=42, test_size=0.25, stratify=y)
Now, we use the CountVectorizer to parse the text data into a bag-of-words model.
from sklearn.feature_extraction.text import CountVectorizer print('CountVectorizer defaults') CountVectorizer()
CountVectorizer(analyzer='word', binary=False, decode_error='strict', dtype=<class 'numpy.int64'>, encoding='utf-8', input='content', lowercase=True, max_df=1.0, max_features=None, min_df=1, ngram_range=(1, 1), preprocessor=None, stop_words=None, strip_accents=None, token_pattern='(?u)\\b\\w\\w+\\b', tokenizer=None, vocabulary=None)
vectorizer = CountVectorizer() vectorizer.fit(text_train) X_train = vectorizer.transform(text_train) X_test = vectorizer.transform(text_test)
len(vectorizer.vocabulary_)
7453
>>> 4180 emails * 7453 vector(of words count)
X_train.shape
(4180, 7453)
print(vectorizer.get_feature_names()[:20])
print(vectorizer.get_feature_names()[2000:2020])
print(X_train.shape) print(X_test.shape)
1.1 Training a Classifier on Text Features
We can now train a classifier, for instance a logistic regression classifier, which is a fast baseline for text classification tasks:
from sklearn.linear_model import LogisticRegression clf = LogisticRegression() clf
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1, penalty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False)
clf.fit(X_train, y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1, penalty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False)
We can now evaluate the classifier on the testing set. Let's first use the built-in score function, which is the rate of correct classification in the test set:
clf.score(X_test, y_test)
0.98493543758967006
We can also compute the score on the training set to see how well we do there:
clf.score(X_train, y_train)
0.99832535885167462
1.2 Visualizing important features
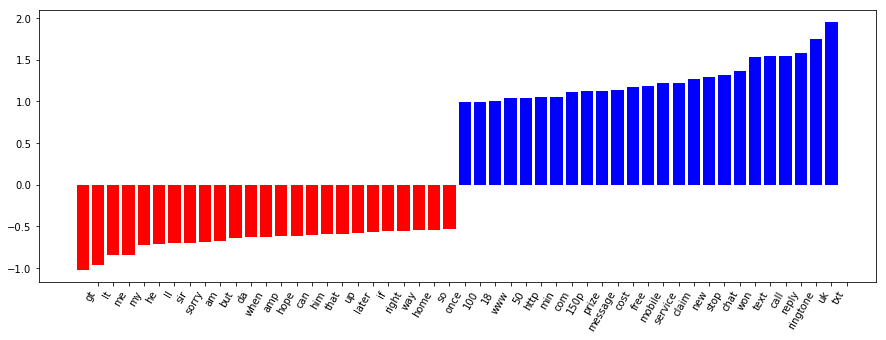
def visualize_coefficients(classifier, feature_names, n_top_features=25): # get coefficients with large absolute values coef = classifier.coef_.ravel() positive_coefficients = np.argsort(coef)[-n_top_features:] negative_coefficients = np.argsort(coef)[:n_top_features] interesting_coefficients = np.hstack([negative_coefficients, positive_coefficients]) # plot them plt.figure(figsize=(15, 5)) colors = ["red" if c < 0 else "blue" for c in coef[interesting_coefficients]] plt.bar(np.arange(2 * n_top_features), coef[interesting_coefficients], color=colors) feature_names = np.array(feature_names) plt.xticks(np.arange(1, 2 * n_top_features + 1), feature_names[interesting_coefficients], rotation=60, ha="right");
visualize_coefficients(clf, vectorizer.get_feature_names())
vectorizer = CountVectorizer(min_df=2) vectorizer.fit(text_train) X_train = vectorizer.transform(text_train) X_test = vectorizer.transform(text_test) clf = LogisticRegression() clf.fit(X_train, y_train) print(clf.score(X_train, y_train)) print(clf.score(X_test, y_test))
len(vectorizer.get_feature_names())
3439
print(vectorizer.get_feature_names()[:20])
visualize_coefficients(clf, vectorizer.get_feature_names())
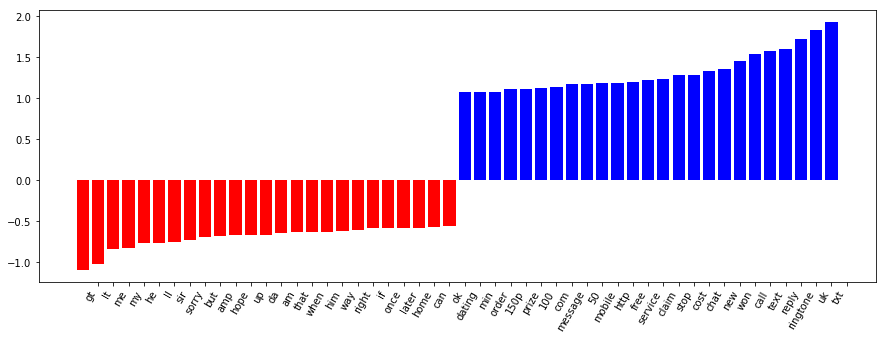
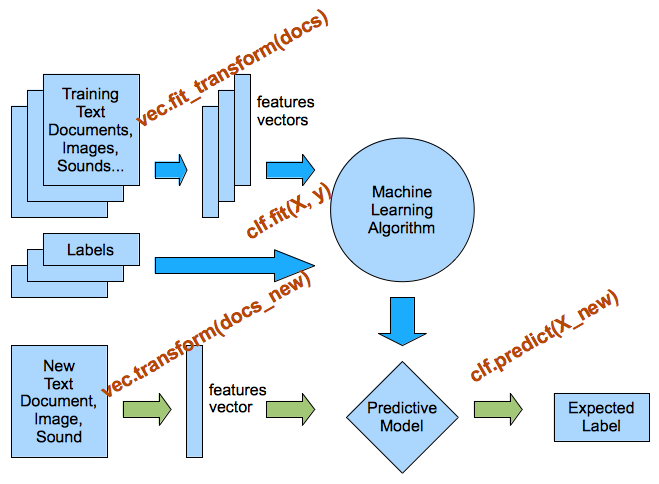
EXERCISE: Use TfidfVectorizer instead of CountVectorizer. Are the results better? How are the coefficients different? Change the parameters min_df and ngram_range of the TfidfVectorizer and CountVectorizer. How does that change the important features?