lec-11 Why Deep
Table of Contents
1 Why Deep
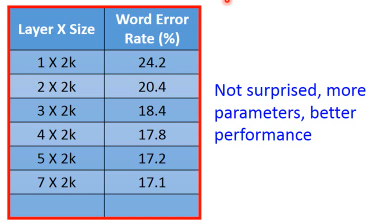
应该调整,让两者参数相等: Fat+short vs. Thin+Tall 这样作比较才有意义
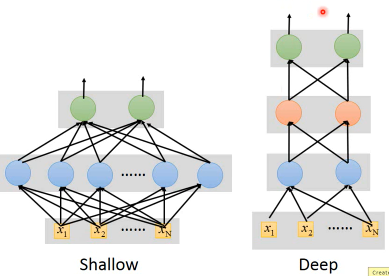
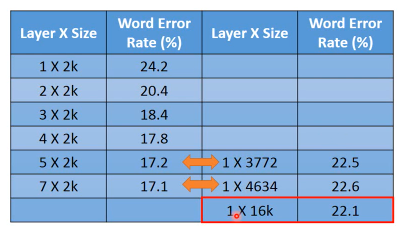
注意,最后三层的比较,是相同参数下的比较。不是相同的神经元数量,是相同的参数数量。
1.1 Modularization
============
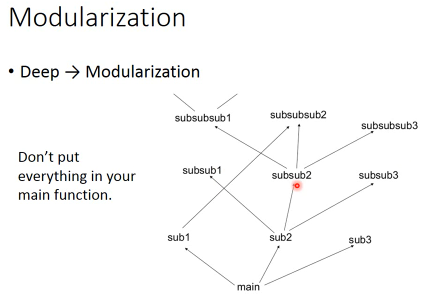 Deep 可以类比 模组化模组化的好处是,有些函数是可以·「共用」的,可以实现·「更高级的抽象」
Deep 可以类比 模组化模组化的好处是,有些函数是可以·「共用」的,可以实现·「更高级的抽象」
1.1.1 why modularization make [less data requirement]
比如,我想对人群分四类:长发女,短发女,长发男,短发男。
=======> 解法一,直接做所以我需要四个二元分类器,把每一类跟其他区分开。但是由于长发男·「很少」,所以这个分类器对于长发男的·「区分能力很弱」
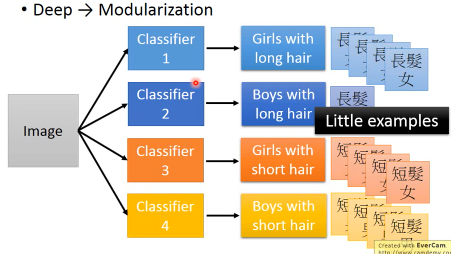
=======> 解法二,分而治之现在用·「模组化」的思想:不直接去解那个问题,而是把他·「分而治之」。
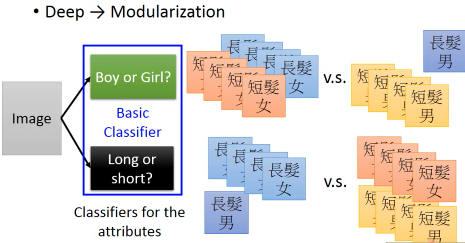
把问题,先分成两个 basic classifier: 男生/女生分类器,长发/短发分类器。这样做的好处是:
- 虽然长发男的样本很少,但是 男生的比例 并不少
- 虽然长发男的样本很少,但是 长发的比例 并不少
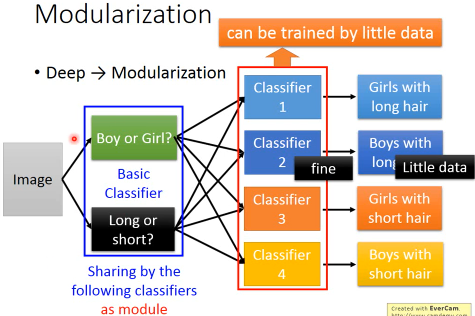
===> 这样就规避了某一类·「样本非常少」对分类器·「能力」的消极影响 ===> Each basic classifier can have sufficient training examples
这样基本分类器的训练是不受·「少样本」影响的,而高级分类器使用·「基本分类器作为输入」,这有点类似于functional programming function as paramerter.所以高级分类器的能力也得以保证。
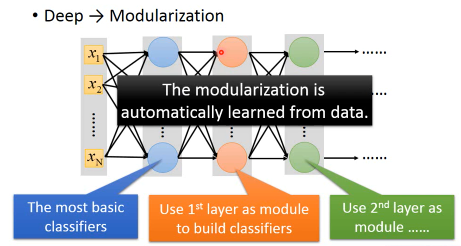
DeepLearning 与 functional programming 所不同的是:函数之间的嵌套关系是由NN模型自动决定的
所以·「模组化」的精神对于深度学习来说,就是 Less training data and unbalanced data DeepLearning need less data!
机器学习与大数据是相反的,正是因为没有足够的数据,所以我们需要深度学习 机器学习不是 brute-force method
利用·「模组化」思想,规避·「数据太少」的问题 Deep Learning need less training data, can deal with unbalanced data
1.1.2 Modularization — Image
======================
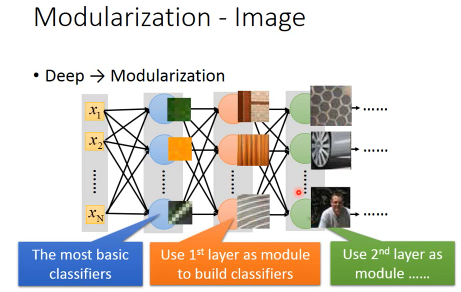
1.1.3 Modularization — Speech
=======================
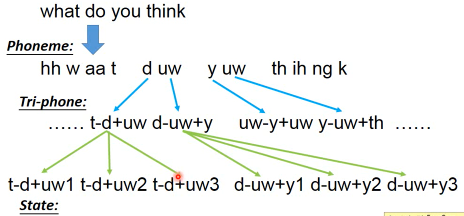
- The hierarchical structure of human languages
人类发音的基本单位是 phoneme 由于人类口腔发音器官的限制,同样的 phoneme 可能会有不同的发音,他会受·「前后phoneme」的影响。所以为了表达这种不同,我们会给同样的phoneme不同的model — tri-phone 比如相同的 uw 因为处在不同的发音环境中,所以给他们不同的model描述。一个 tri-hpone 可以有多个(一般是3个) state
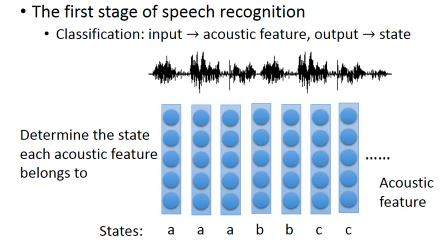
The first stage of speech recognition Classification: input -> acoustic feature, output -> state acoustic feature 是什么呢?简单来说,声音讯号就是一串波形,在这个波形上取一个窗口(250ms),用一个向量来描述这个窗口中波形的特性,这就是 acoustic feature.每个窗口都‘罩’这一段声音波形,所以一整段语音就是一个 vector sequence,acoustic feature sequence. 语音辨识第一步要做的就是 辨识每一个 vector(acoustic feature)所属于的state
但是只有这个是没法做语音辨识系统的,下一步要把state转成phoneme,然后再把phoneme转成文字。还要考虑诸如同音异字的问题,等等。
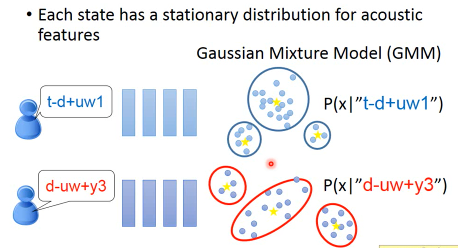
比较传统语音辨识与深度学习语音辨识 Traditinary method(Only 1st step) Each state has a stationary distribution for acoustic features 但是这样做不work的,一般语音都有30个左右的phoneme,随着上下文的不同你有不同的 model,再每一个model都有3种state。总计,你有 30×30×30×3 = 8.1w 个state。而每一个state都要用一个 Gaussian mixture model 来描述,参数太多了,training data根本不够。怎么办呢?
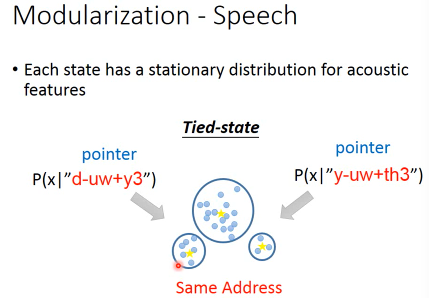
传统的方法:有一些state会共用 GMM,这叫做 :Tied-state. 什么叫不同的state共用同样的分布呢?把state类比C语言中的指针,把GMM类比C语言中的地址。不同的指针(state)可以指向相同的地址(GMM)。哪些state是共用的,这个依靠经验和语言学思想。而且有些state要共用,或不共用的说法,太粗糙了,所以有人提出·「部分共用」有些人引出一个概念:subspace GMM,也是一种模组化. 原来是说,每一个state对应一个gaussian。现在是先把很多很多的 Gaussian 先找出来,这就是 gaussian pool。而state的infomation就是一个key,key告诉我们这个state他会从pool中挑那些gaussian。比如,state-1 choose gaussian1,3,9 from pool. state-2 choose gaussian1,7,9 from pool. 但是具体states,会如何share gaussian,就要通过数据来学习出来

母音的发音,只受到三件事情的影响:舌头的前后位置,舌头的上下位置,嘴形。从图中可以看到,i,e,u,o,a, 这五种英文母音,i,u之间的差别仅仅是舌头的前后位置; i,e,a的区别仅仅是舌头的上下位置, 而图中同一位置的不同发音是由·「嘴形」的不同造成的。比如 i,y 舌头上下前后的位置都相同,不同的是·「嘴形」。
所以人声的不同的phoneme之间是有关系的,不是 indenpendent 的。每一个hponeme都搞一个自己的model,很没有效率
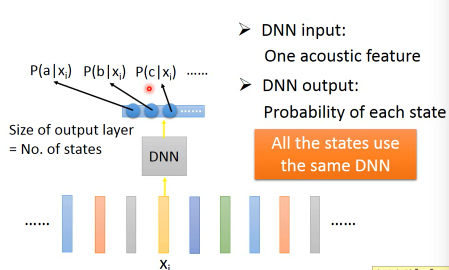
DNN 处理 speech recognition input: one acoustic feature outpu: probability of each state 这边为什么有效率呢? 因为所有的state都共用同一个DNN 传统的HMM-GMM, 每一个state都有一个Gaussian mixture model.
DNN 只有一个很大的 model。 GMM 用了很多很小的 model。
但是两者使用的参数数量其实是差不多的,DNN牛逼并不是因为参数多/模型强,而是因为 modularization
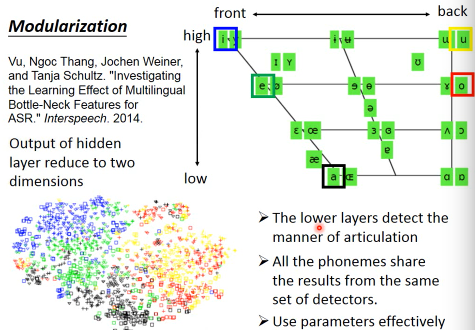
为什么DNN的方式更好把DNN中某一个隐含层的输出拿出来做降维,降到两维,然后画出来这里的颜色就是 i e u o a 对应的颜色。惊奇的是,图中这五种颜色的分布是和这五个母音的分布其实几乎是一样的。所以DNN比较底层的隐含层在做的事情是:当你听到某个母音时,人类是用什么·「嘴形和舌形」发音的。
接下来的layer,才根据这个结果决定现在的发音是属于哪一个state 所以, lower layer 是一个人类发音的 detector。 high layer 用同一组 detector 完成所有 phoneme 的侦测。
这就是一种模组化。当你使用模组化的时候,你就是在·「复用」。这样的参数会比较少,整体也比较有效率。
当你使用模组化的时候,你就是在·「复用」。这样整体的参数会比较少,整体也比较有效率。
1.2 Universality Theorem
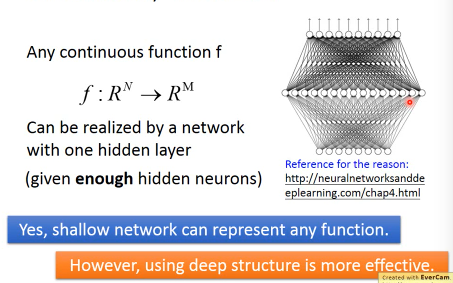
However, using deep structure is more effective. Although shallow network can represent any function.
1.3 Some Analogy
1.3.1 Analogy(逻辑电路)
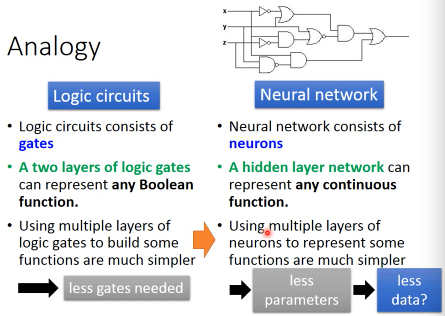
对函数(逻辑电路)的复用,带来更少的参数量要求,进一步带来更少的数据量要求所以深度学习,不是·「暴力搜索」式的算法,而是·「四两拨千斤」的算法。
1.3.2 More Analogy
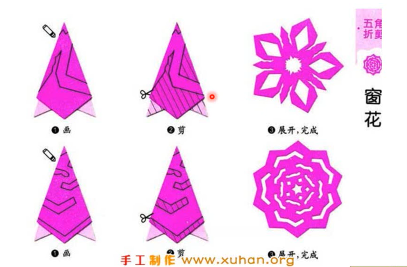
不是直接剪出右边的窗花,而是先折起来再剪
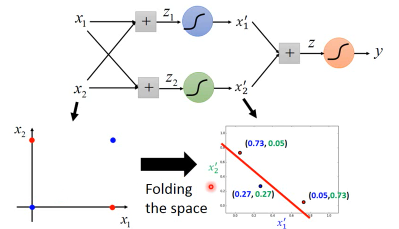
这个分类,就像是把·「空间对折」一样
剪窗花:training 画斜线的部分:positive 没画斜线:negative 折叠窗花:folding-space 所以你只要在折叠窗花上略做裁剪,就可以得到复杂的窗花图案。原始空间中的非线性分类,就是折叠空间中的线性分类
另一个角度,你在折叠窗花上戳一个洞,就会在原始窗花上看到五个洞。一笔折叠窗花上的数据,就相当于原始窗花上的五笔数据。
Use data effectively
1.3.3 More Analogy - Experiment
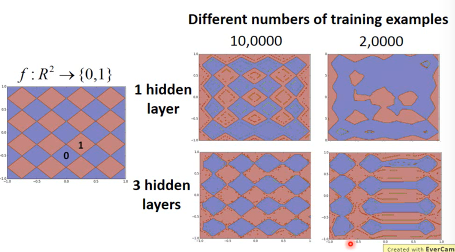
1.4 End-to-end Learning·「没听懂:为什么叫端到端学习」
使用深度学习的另一个好处是可以实现·「端到端的学习」有时候要处理的问题非常的复杂,也就是要获得一个很复杂的函数。这时候要做的
1.4.1 End-to-end Learning Speech Recognition
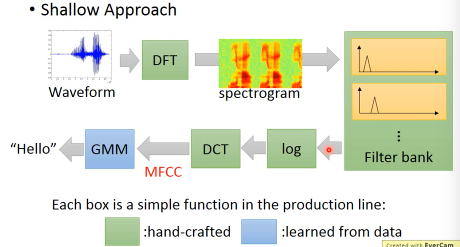
这里我快被李宏毅老师笑死了:他说,这个模型就是·「古圣先贤」研究了各种人类生理知识之后呢,搞了不知多久搞出来的生产线,简直是·「增一分太肥,减一分太瘦」,因为古圣先贤都太厉害了,卡在这个生产线卡了几十年的样子。
直到现在也只能用DNN取代GMM,MFCC,DCT这一段从 log 部分开始做DNN
甚至你可以从 spectrogram 部分开始做DNN
但是DNN没法替代DFT,这个transform似乎是一个极限,再深的DNN做的事情好像也就是对DFT的模拟
1.4.2 End-to-end Learning Image Recognition
1.5 Complex Task
==========
- Very similar input, different output

- Very different input, similar output
- 同样的声音讯号,不同的人说出来,是很不一样的
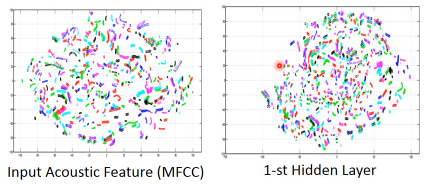
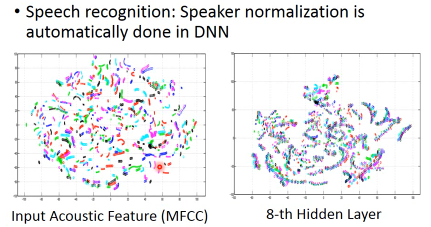 不同的颜色区分不同的人的发音不同的人说同样的话,在MFCC中完全就是分开的。但是在8-th隐含层的DNN中,被划分成了各种不同的·「线」相同的话语内容,被分在一起了。
不同的颜色区分不同的人的发音不同的人说同样的话,在MFCC中完全就是分开的。但是在8-th隐含层的DNN中,被划分成了各种不同的·「线」相同的话语内容,被分在一起了。
MNIST - handing write recognition

1.6 Some paper about why deep
• Deep Learning: Theoretical Motivations (Yoshua Bengio) • http://videolectures.net/deeplearning2015_bengio_theoretical_motivations/ • Connections between physics and deep learning • https://www.youtube.com/watch?v=5MdSE-N0bxs