lec-19 Transfer Learning
Table of Contents
1 Transfer Learning
似乎 transfer 就是决定复用 哪些层,那些可以复用的层就叫做 transfer layer
- Similar domain, different tasks
- Different domains, same task
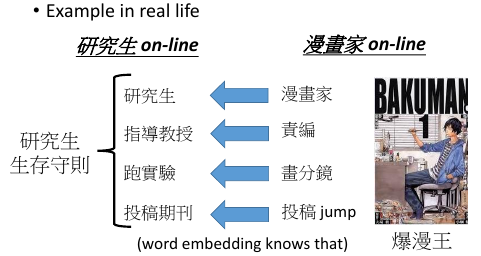
研究生该怎么做?可以参考漫画家的工作过程我们日常生活中,经常干这样的事情
1.1 Transfer Learning 的四种可能
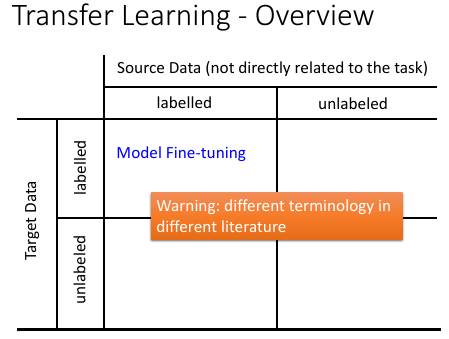
- target data 是与我们的 task 直接相关
- source data 是与我们的 task 无直接关系
[无直接关系的定义学界比较混乱,但大概可以理解一下]
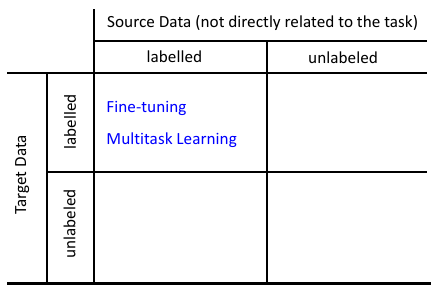
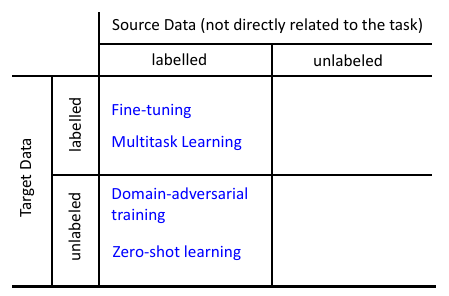
2 如果 source 有 label, target 有 label
2.0.1 Model Fine-tuning
One-shot learning: only a few examples in target domain
- Task description
- Target data: x t , y t –> Very little
- Source data: x s , y s –> A large amount
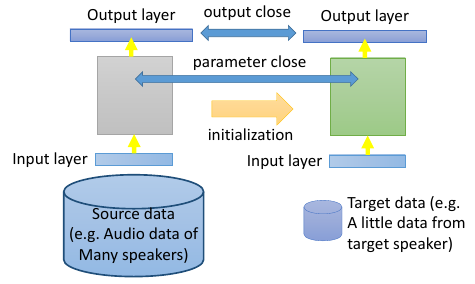
- Example: (supervised) speaker adaption
- Target data: audio data and its transcriptions of specific user
- Source data: audio data and transcriptions from many speakers
- Idea: training a model by source data, then fine-tune the model by target data
- Challenge:
only limited target data, so be careful about overfitting
极端情况:One-shot learning: target data 少到只有很少的幾個就是 one-shot learning
什么叫做 fine-tune 就是用 source data train 一个模型,然后把这个模型 train 出来的参数当作初始值然后结合 target data 去 train 一个新的同样的模型。
如果 target data 少的好像 one-shot learning 一样,结果依然很差,怎么办?
有很多不同的技巧来解决这个问题:
2.0.2 技巧 1:Conservative Training
加一个 constrait,也就是一个 regular:新旧 model 在同一笔 data 上的结果不要太 大就可以防止 overfitting 的情形 [qqq] ------------------------------------------------- 这里为甚么是防止 overfitting 啊? 防止谁 overfitting? 是 source data 训练出来的模型 太厉害,远远超逾 target data 数量所能 hold 的模型复杂度? -------------------------------------------------
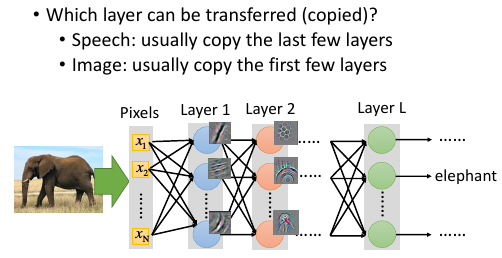
2.0.3 技巧 2:Layer Transfer
source data train 好的 model, 从中直接 copy 一部分 layer到 target data 要训练的模型中去,然后 target data 只需要考虑那些没有被 copy 的 layer.
这样 target data 只需要考虑很少的 parameter, 所以可以避免 overfitting搞完之后呢,如果 target data 够的话,整体做一个 fine-tune
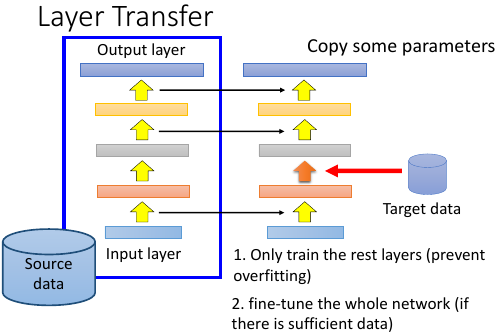
但是哪些 layer 应该 copy 过去呢?
不同的 task 需要 copy 不同的 layer.
语音上,不同的人用同样的发音方式,因为口腔结构略有差异,所以得到的声音讯号是不一样的。speech 面向的 NN ,前几层是区分语者不同的发音方式,从发音方式到辨识结果是跟语者没有关系的这几层可以 copy.
图像识别上,要 copy 前面几层,因为前面几层就是 detect 有没有一些纹路,形状等等。所以这前几层是可以 被 transfer 到其他 target data 上的。因为这一部分大家是共用的。
似乎 transfer 就是决定复用 哪些层,那些可以复用的层就叫做 transfer layer
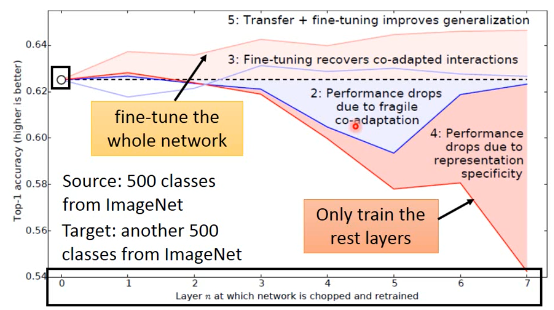
- 横轴是 copy 前几个 layer
- 纵轴是 模型的误差
下面这张图,可以用来发现,两个不同领域的模型,哪些层做的事情是差不多的图片分类,sourcedata 是分动物,targetdata 是分家具,依次 copy前 1~7 层看看两者的差距从哪里开始拉开,这样可以验证从哪一层可以开始复用。以后用在分交通工具。
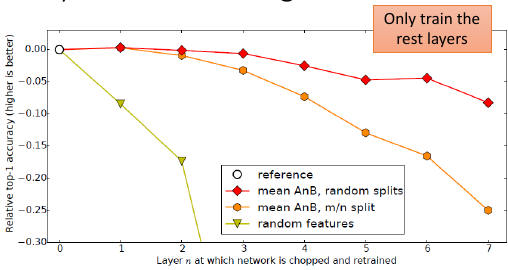
- Jason Yosinski, Jeff Clune, Yoshua Bengio, Hod Lipson, “How transferable are features in deep neural networks?”, NIPS, 2014
- Fine-tune 关注的是 target-domain 做的好不好。
- Multitask learning 同时关注 target and source domain
2.0.4 Multitask learning
Deep learning 特别适合做 multitask learning
- The multi-layer structure makes NN suitable for
multitask learning
- 共通的 feature
- 不同的 feature
2.0.5 Multitask Learning 的成功例子
不同语言下的语音辨识这个 model 可以同时辨识 5 种语言
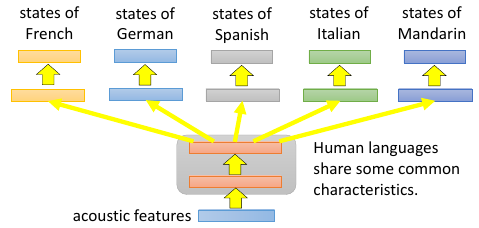
translation 也是一样的道理
Similar idea in translation: Daxiang Dong, Hua Wu, Wei He, Dianhai Yu and Haifeng Wang, "Multi-task learning for multiple language translation.“, ACL 2015
经过最近几年,发现几乎所有的语言都可以互相 transfer
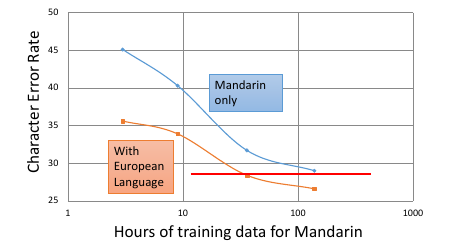
Huang, Jui-Ting, et al. "Cross-language knowledge transfer using multilingual deep neural network with shared hidden layers." ICASSP, 2013
Progressive Neural Networks
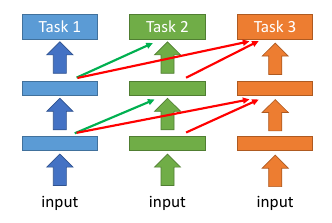
Andrei A. Rusu, Neil C. Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Razvan Pascanu, Raia Hadsell, “Progressive Neural Networks”, arXiv preprint 2016
3 如果 source 有 label, target 没有 label
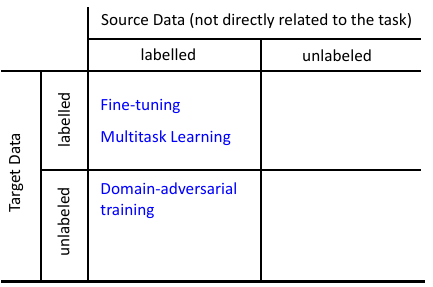
- Source data: xs , ys —> Training data
- Target data: xt —> Testing data
两者非常的 mismatch

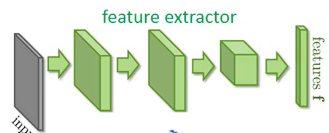
如果我就直接用 source 去 train 一个 model 然后用到 target 上去。结果很差。通过之前的学习,我们知道 DNN 前面的几层基本就相当于一个 feature extractor 后面的几层基本就是一个 classifier
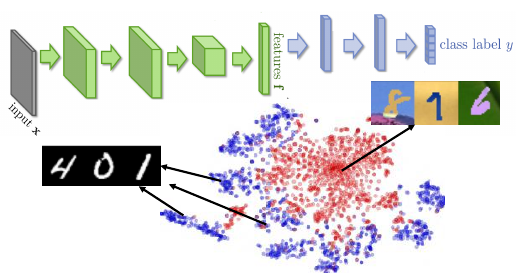
如果把前面几层的结果拿出来 做一个 t-sne 做 visualization可以发现,target data extract 出来的 features 跟用 source data extract 出来的 features 完全不在一个位置上。也就是说,
前面的这些绿色层从 source data 和 target data 抽取的是不一样的 feature.
3.0.1 Domain-adversarial training
原理跟 GAN 的 ‘A’ 相似: 所以我们希望,前面的 extractor 可以不那么【domain specific】,我们希望想个办法把前面几层变的更【通用一些】,把 domain specific 的特性去掉。希望它可以 extract 之后的结果是【混在一齐】.
从
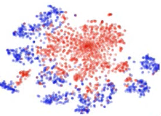
变成
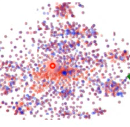
这里怎么做呢?加入一个 domain classifier 用来判断,抽取出的某个属性,到底是哪个 domain 的.

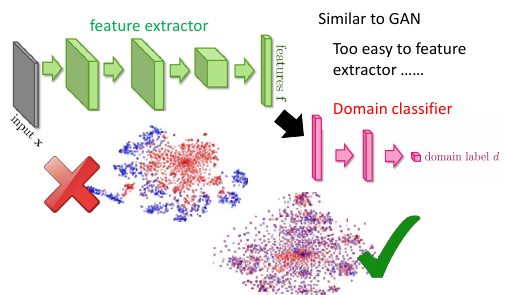
- feature extractor ==> GAN 的 生成器
- domain classifier ==> GAN 的 鉴别器
这里要比 GAN 容易, 但是要给 feature extractor 添加一个任务:不但要【骗过】 domian classifier, 还要满足 label classifier 的要求。
3.0.2 一个各怀鬼胎的神经网络
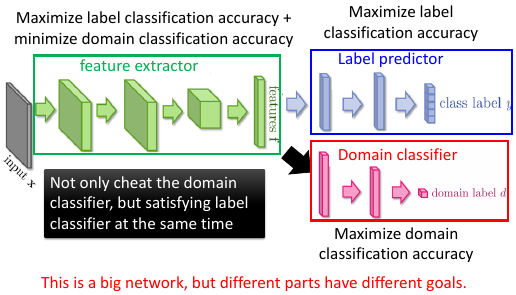
可以发现 feature extractor 这一部分的一个目标是违反 domain classifier 的
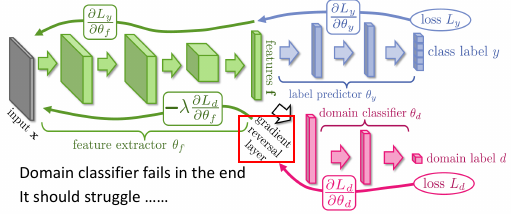
- Yaroslav Ganin, Victor Lempitsky, Unsupervised Domain Adaptation by Backpropagation, ICML, 2015
- Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, Domain-Adversarial Training of Neural Networks, JMLR, 2016
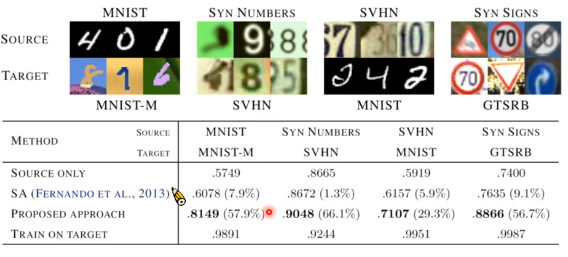
此表 Proposed Approach 就是这里的方法。
3.0.3 zero-shot learning
就是完全没有标签
- Source data: x s , y s Training data
- Target data: x t Testing data
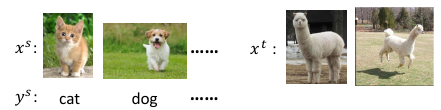
这里你让 xt –> 草泥马, 这个也太难了点了。
In speech recognition, we can not have all possible words in the source (training) data. How we solve this problem in speech recognition?
但是这件事情在语音转文字是有解决方案的,英文单词每天都在产生,舶来词,网络词,等等,而這些词发音容易,但要计算机给出這些单词的拼写字幕,是非常难的。
降低分类单位, 不要直接把语音转成文字,而是把语音转成音标(phoneme)然后 phoneme 和 单词之间建立一个 table(字典)
那在草泥马这个图像识别上怎么做呢?
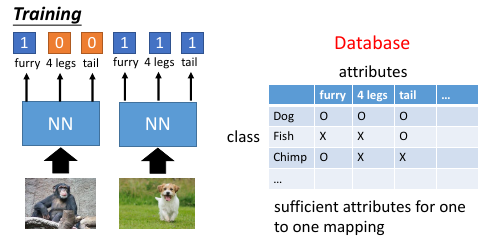
phoneme —> attributes attributes ===> 毛茸茸,四肢脚,有尾巴,。。。
3.1 Attribute embedding
如果 attribute 很复杂,可以做 embedding
3.1.1 >>> embedding tip
------------------------------------------------- 看李宏毅老师是如何理解 embedding 的,embedding 也跟 regular一样被李老师【范 化】成了一个通用的工具,可 以任意的添加在某个模型里。 -------------------------------------------------
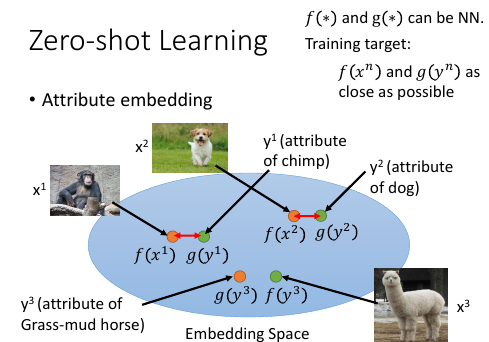 [勘误]: f(y3) ==> f(x3)
也就是说,现在有一个 embedding 的 space, 然后把训练集数据 x 都透过一个 transform 转换成 embedding-space 的一个点,
x –> f(x)
然后把所有的 attribute 也都变成 embedding-space 上的一个点
y –> g(y)
这个 g 和 f 都可以是 NN
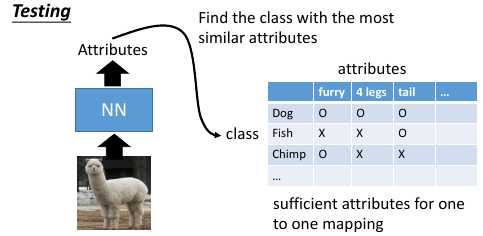
那么 training 的时候就希望 f(xn) ~~ g(yn) 越接近越好在做 testing 的时候就看这个点的 attribute 做 embedding 以后跟哪一个 attribute 最像,你就知道了他是什么样的 image
[勘误]: f(y3) ==> f(x3)
也就是说,现在有一个 embedding 的 space, 然后把训练集数据 x 都透过一个 transform 转换成 embedding-space 的一个点,
x –> f(x)
然后把所有的 attribute 也都变成 embedding-space 上的一个点
y –> g(y)
这个 g 和 f 都可以是 NN
那么 training 的时候就希望 f(xn) ~~ g(yn) 越接近越好在做 testing 的时候就看这个点的 attribute 做 embedding 以后跟哪一个 attribute 最像,你就知道了他是什么样的 image
>>> 学生问题这边把 attribute embedding 进去是什么意思啊? >>> 李老师回答 attribute 就是一个 vector 嘛,然后把这个 vector 乘以一个 transform, 然后把他丢到一个 NN 里面去。然后 NN 会 output 一个 vector 吧。也就把一个 vector 变成了另一个 low-dimension vector. 你可以想成是做【降维】的意思 >>> 学生再问那所以就是这一个 embedding 的过程,他的 input 可以是一个 image 也可以是一个 attribute,但是要用不同的 transform,因为 image 和 attribute 是差很多的。然后我们就希望经过两个 NN 之后产生的结果,是非常接近的。
image 和 attribute 都可以描述成 vector,这里想要做的事情是把 image 和 attibute 同样的同一个空间里面, 可以理解成对 image-vector 和 attibute-vector 同时做降维降到相同的维度数。 所以把 image: x1,x2,.. 通过 f 转换到 embedding 上的点,把 attribute: y1,y2,… 通过 g 也转换到 embedding 上的点,但是怎么找这个 f,g 呢?既然是函数是转换,我就可以用 NN. 我要做的其实就是通过两个 NN 找到 f,g 让他们在某个空间(embedding space)完成【配对】。配对就是重叠。(我发现 NN 有个能把所有不咋相关的事务‘相关化’的能力,image-vector 都是一些像素点组成的向量,attribute-vector 都是一些实体的特色组成的向量,两者在各自原来的空间中八竿子打不着,要把他们配对必须把他们拉到某一个相同的空间里)。现在假设 f,g 已经找到,新来一张 image,我要找他的【配偶】我就可以先通过 f 把他拉到这个 embedding 空间里。因为是新的图片,所以这个 embedding-space 里面是没有他的【配偶】的,但是我可以找一个离他最近的点,至少这个点应该【长得像】他的配偶。
3.1.2 借用 word-vector
What if we dont have a database
如果我根本不知道每一个动物对应的 attribute 是什么,该怎么办呢?
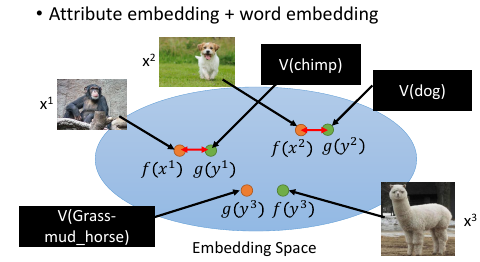 可以借用 word-vector
word-vector 的某个 dimension 就带表这个 word 的某种 attribute
所以你不一定需要一个 database
你就把 attribute 直接换成 word-vector,也做跟刚才一样的事情。
可以借用 word-vector
word-vector 的某个 dimension 就带表这个 word 的某种 attribute
所以你不一定需要一个 database
你就把 attribute 直接换成 word-vector,也做跟刚才一样的事情。
重新设计 loos-fn [类间大][类内小] 刚才的思路只是在 最小化 一对夫妻的距离,但是【对跟对之间的距离没有考虑】
3.1.3 >>> 区间控制:[类间大][类内小] tip
注意:argminfg Σ||fx - gx || 是没有考虑 [类间大] 的。看看李老师是如何改进这个 loss-fn 的 argminfg Σ max(0, k - f*gm=n + f*gm≠n) [类间大]这个间距似乎就是 svm 的强项我们 hold 住了 loss-fn 的最小值,lossfn 最小为 0 丈夫跟自己的老婆的距离有多近呢? k - f*gm=n + f*gm≠n < 0 => f*gm=n - f*gm≠n > k 丈夫跟不是自己老婆的所有女人中关系最近的哪一个的关系,比跟自己老婆的关系都要远一个 k
这个函数经典,张弛有度:首先这个函数是要越小越好,所以比较大的都会被干掉,比如 k - f*gm=n + f*gm≠n > 0, 说明【跟配偶之外的异性关系暧昧】越暧昧这个值越大就越会被干掉。其次,f*gm=n - f*gm≠n 这个值不是越大越好么,最好无限大,‘水至清则无鱼’有可能一个点都找不到。所以设置了一个阈值,只要比这个阈值大就是可以接受的。所以想要 hold 住一个【区间】就是用这个函数: max(0, 阈值-距离)
3.1.4 ConSE: Convex combination of semantic embedding
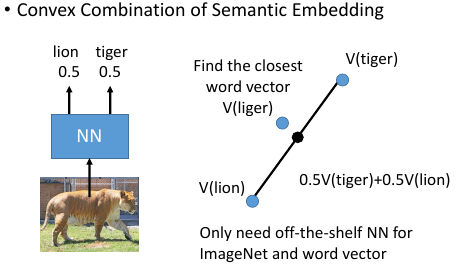 这个就是借用,你从网络上 download
一个已经 train 好的 off-the-shelf 图像辨识系统和一个已经 train 好的 off-the-shelf work2vec
这个就是借用,你从网络上 download
一个已经 train 好的 off-the-shelf 图像辨识系统和一个已经 train 好的 off-the-shelf work2vec
- 一张图丢进 NN 他可能输出 0.5 狮子,0.5 老虎
- 找 lion tiger 的 word-vector,用刚才的比例混合
- 找一个 word-vector 跟按比例混合之后的结果最接近
这里你不需要任何 training, 只要两个现成的模型就可以做图像 –> 文字这种识别了。
3.1.5 DeVISE
把 word-vector 和 NN 都 project 到同一个 embedding space
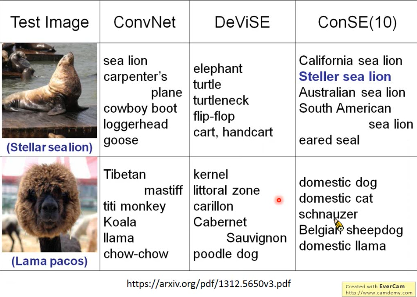
3.1.6 ConvNet. vs DeViSE. vs ConSE(10)
3.1.7 Example of zero-shot learning
Melvin Johnson, Mike Schuster, Quoc V. Le, Maxim Krikun, Yonghui Wu, Zhifeng Chen, Nikhil Thorat. Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation, arXiv preprint 2016
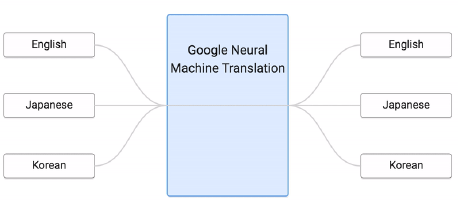
这个翻译机,从来没看过韩语到日语的翻译,但他看过其他种类的各种翻译。但是学习之后,他可以很好的把韩语翻译成日语。
把不同语言的不同句子 project 到同一个 embedding space 上面而这个 embedding space 是 language-independent 的。这个 embedding space 上的位置只跟这个句子的语义有关,跟具体的语言无关。
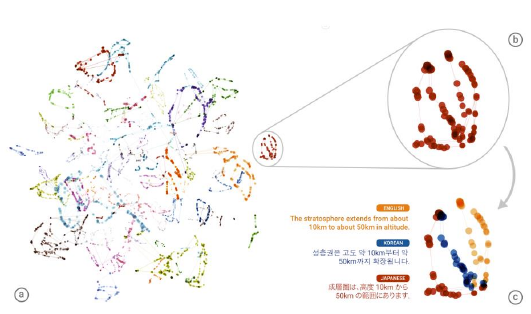
根据 learn 好的 translator, translator 有一个 encoder, 他会把 input 的句子变成 vector, dicoder 根据这个 vector 解成一个句子,这就是翻译的过程。
如果把很多语言的同一个意思的句子通过 encoder 映射到这个 embedding space 中,可以发现他们处于很相近的位置上。图中同一个颜色代表同样的语义但是他们可以来自不同的语言。可以把这个 embedding space 看成是一种 [新的语言]
3.1.8 More about Zero-shot learning
- Mark Palatucci, Dean Pomerleau, Geoffrey E. Hinton, Tom M. Mitchell, “Zero-shot Learning with Semantic Output Codes”, NIPS 2009
- Zeynep Akata, Florent Perronnin, Zaid Harchaoui and Cordelia Schmid, “Label-Embedding for Attribute-Based Classification”, CVPR 2013
- Andrea Frome, Greg S. Corrado, Jon Shlens, Samy Bengio, Jeff Dean, Marc'Aurelio Ranzato, Tomas Mikolov, “DeViSE: A Deep Visual-Semantic Embedding Model”, NIPS 2013
- Mohammad Norouzi, Tomas Mikolov, Samy Bengio, Yoram Singer, Jonathon Shlens, Andrea Frome, Greg S. Corrado, Jeffrey Dean, “Zero-Shot Learning by Convex Combination of Semantic Embeddings”, arXiv preprint 2013
- Subhashini Venugopalan, Lisa Anne Hendricks, Marcus Rohrbach, Raymond Mooney, Trevor Darrell, Kate Saenko, “Captioning Images with Diverse Objects”, arXiv preprint 2016
4 如果 source 没有 label
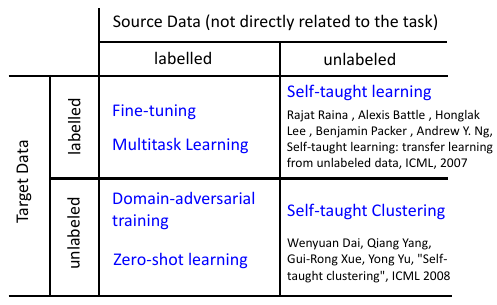
Self-taught learning
Rajat Raina , Alexis Battle , Honglak Lee , Benjamin Packer , Andrew Y. Ng, Self-taught learning: transfer learning from unlabeled data, ICML, 2007
Self-taught Clustering
Wenyuan Dai, Qiang Yang, Gui-Rong Xue, Yong Yu, "Self- taught clustering", ICML 2008
注意,之前也学过,semi-supervised learning. 也是有 labelled and unlabelled data. 但是两者有本质的区别,semi 中的 labelled 和 unlabelled 还是有很多关系的,只是没有标签。
而这里是说,两者完全来自不同的 domain,是几乎没有什么关系的。
Self-taught learning
- Learning to extract better representation from the source data (unsupervised approach)
- Extracting better representation for target data
4.0.1 处理 unlabelled data 的思路
总之如果 source data 是 unlabelled data可以 learn 一个 feature extractor. 你可以用 auto-encoder 来 learn 这个 feature extractor. 或者 learn 一个好的 representation.
然后用这个 feature extractor or good representation 去 target data 上去抽 feature.