lec-21 Structure Learning
Table of Contents
1 Structure Learning
之前讲的所有的 input 和 output 都是 vector 但是实际遇到的问题会比 vector 复杂的多的 object • We need a more powerful function f • Input and output are both objects with structures • Object: sequence, list, tree, bounding box …
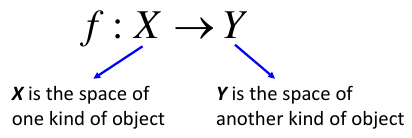 In the previous lectures, the input and output are both vectors.
In the previous lectures, the input and output are both vectors.
1.1 Example Application
=================
• Speech recognition
• X: Speech signal (sequence) → Y: text (sequence)
• Translation
• X: Mandarin sentence (sequence) → Y: English sentence (sequence)
• Syntactic Paring
• X: sentence → Y: parsing tree (tree structure)
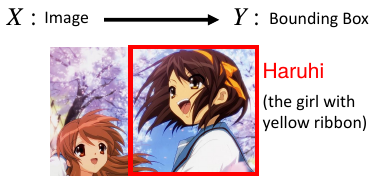
• Object Detection
• X: Image → Y: bounding box
• Summarization
• X: long document → Y: summary (short paragraph)
• Retrieval
• X: keyword → Y: search result (a list of webpage)
1.2 Unified Framework of Structure Learning
=====================================
之前的 Training 是找一个 f: x -> y
之前的 Testing 是找一个 argw min(y-f)
现在的 Training 是找一个
 X 和 Y 都是 structure object,
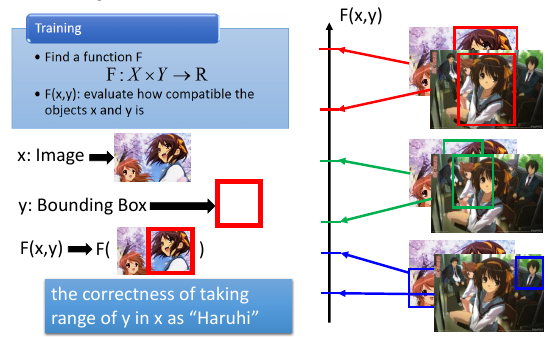
F 是这两个 object 有多匹配
F(x,y): evaluate how compatible the objects x and y is
X 和 Y 都是 structure object,
F 是这两个 object 有多匹配
F(x,y): evaluate how compatible the objects x and y is
现在的 Training 是找一个
 穷举每一个 y, 找到让 F(x,y) 最大化的 y~
穷举每一个 y, 找到让 F(x,y) 最大化的 y~
1.2.1 Unified Framework : Object Detection
• Task description • Using a bounding box to highlight the position of a certain object in an image • E.g. A detector of Haruhi
 还有须多其他应用
还有须多其他应用
也可以用 DeepLearning 来做, DeepLearning 和 StructureLearning 是有很大关系的比如 GAN 是跟 StructureLearning 是非常有关系的,GAN 其实就是在实做刚才讲的这个 UniformFramework,
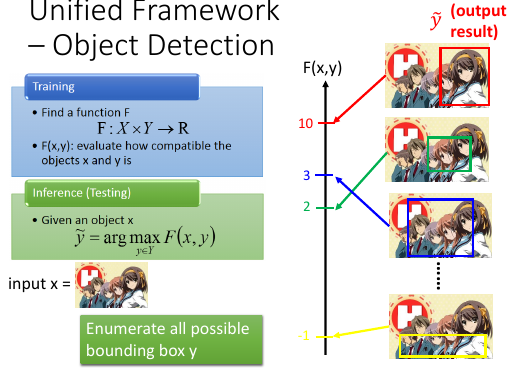
x: 就是这张图 y: 框 F(x,y): 这张图与这个框有多匹配,是否把凉宫春日给框出来 F 的值越高,说明‘框’的越好: F: the correctness of taking range of y in x as “Haruhi”凉宫春日
 从上往下,‘框’的越来越差
从上往下,‘框’的越来越差
Testing 的时候怎么做呢? input 一张新的图片,穷举所有可能的‘框’谁的分数最高,谁就是最后的输出 y y~ = argmaxF(x,y)
1.2.2 Unified Framework - Summarization
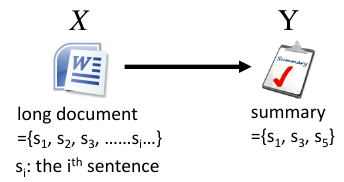
• Task description • Given a long document • Select a set of sentences from the document, and cascade the sentences to form a short paragraph
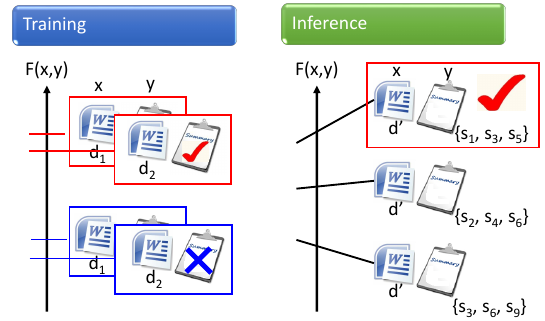 Testing 的时候就穷举所有可能的 Summaries 看哪个 summaries 可以让你的 F(x,y) 最大---x,y 最匹配
Testing 的时候就穷举所有可能的 Summaries 看哪个 summaries 可以让你的 F(x,y) 最大---x,y 最匹配
1.2.3 Unified Framework - Retrieval
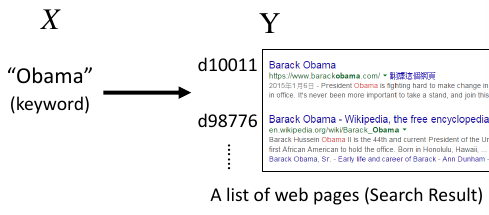
• Task description • User input a keyword Q • System returns a list of web pages
1.3 进一步理解结构学习框架
1.3.1 概率解释下的 Unified Framewrok: Graphical Model
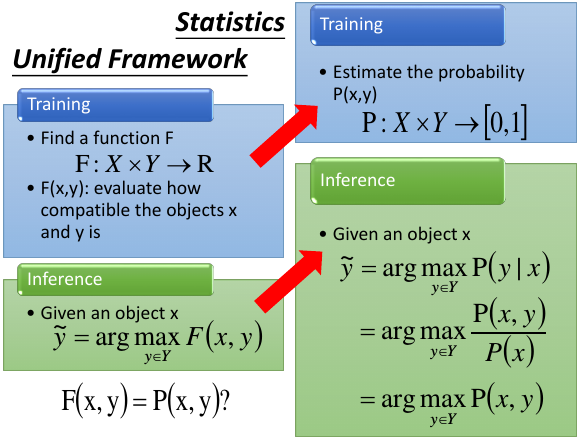
Training 的时候是 Estimate P(x,y) join probability Testing 的时候是 Get y who maximize P(y|x) condition probility
ppt 中 P(x,y)/P(x) = P(x,y) 是因为 P(x) 对 y 没有影响,我只要看哪个 y 能最大化 P(x,y) 即可。
现在 F(x,y) = P(x,y) F(x,y) 表示 x,y 有多匹配 P(x,y) 表示 x,y join-probaility, Training 的时候找到 P(x,y), Testing 的时候找到能最大化 P(x,y) 的 y

Graphical Model 就是 Structure Learning 的其中一种。只是在 Graphical Model 的时候把 F(x,y) 换成了刚才讲的 P(x,y) 比如 Graphical Model 中的 Belief Network 或者 Markov Random Field 他们其实在做一样的事情,也是在找一个 evaluation function(类似 F(x,y))只是他们找的 evalution function 是一个 几率公式
李宏毅老师说,他比较喜欢用 F(x,y)
他觉得用概率有幾個坏处
- Probability cannot explain everything 很多东西不好解释
- 0-1 constraint is not necessary 很多东西很难 normalization
用几率的好处:
- 有时候方便解释很多意义
1.3.2 做 Unified Framework 的三个条件:
- F(x,y)长什么样子? Evaluation: What does F(x,y) look like? • How F(x,y) compute the “compatibility” of objects x and y

- 怎么解 argmax 这个问题这个 y 的集合是很大的,怎么穷举所有的: bounding box, combination of sentence set, webpage ranking • Inference: How to solve the “arg max” problem

- 给了训练样本,如何计算 F(x,y),然后比较谁好谁怀• Training: Given training data, how to find F(x,y)

1.3.3 >>> 神之三问:
• Evaluation: What does F(x,y) look like? • Inference: How to solve the “arg max” problem • Training: Given training data, how to find F(x,y)
GAN 可能就是解决这三个问题的方法! 这三个问题在 数字语音处理课程中的 HMM:Hidden Markov Model 中有提到

1.3.4 Link to DNN?
之前讲的 DNN 就是 structure Learning 的一个 special case
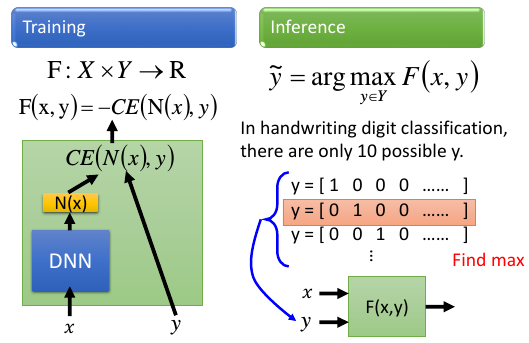
例子:手写数字辨识,输入一张图片 x,输出一个 10 维度向量 N(x), 标签是 y.
利用 cross entropy 来度量两者有多匹配,那么这个 cross entropy 取负就是 F, 而 x 是 input, y 是 label.
在做 inference 也就是 testing 的时候穷举所有的 10 种可能。然后找到能最大化 F(也就是最小化 cross entropy 的 y)
>>> 神之三问:
• Evaluation: F = - cross entropy • Inference: all possible y only has 10 outcome • Training: cross entropy