lec-24 Sequence Labeling Problem
Table of Contents
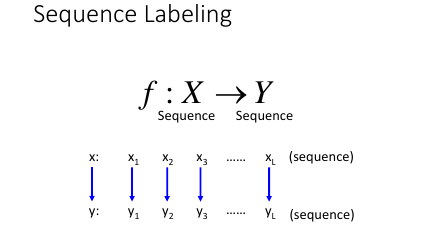
1 Sequence Labeling Problem
 作业二:实现 RNN 与之类似。
作业二:实现 RNN 与之类似。
1.1 Application
标记一个句子中每一个 word 的词性

POS tagging: 语义分析的基础
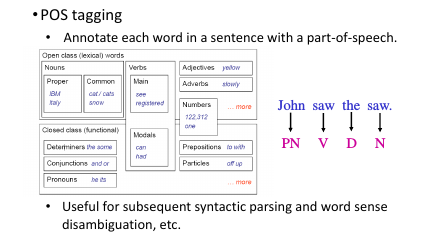
 POS tagging 的问题只靠查表是完全不够的,还要参考整个 word 的上下文关系。
POS tagging 的问题只靠查表是完全不够的,还要参考整个 word 的上下文关系。
1.2 Outline
- Hidden Markov Model (HMM)
- Conditional Random Field (CRF)
- Structured Perceptron/SVM
1.3 Hidden Markov Model (HMM)
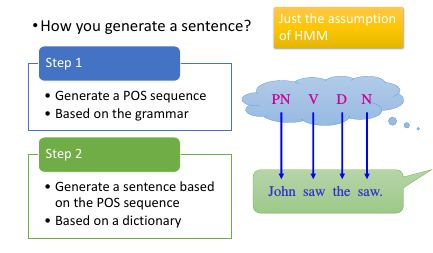
Grammer –> POS sequence –> (dictionary) –> sentence
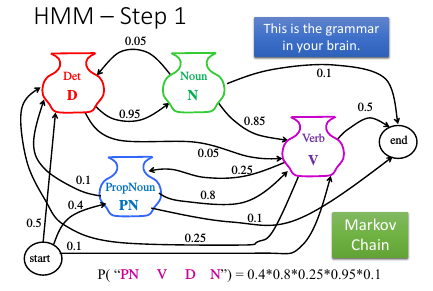
1.3.1 HMM-step 1
‘语法’是什么呢?如何表示? – Markov Chain
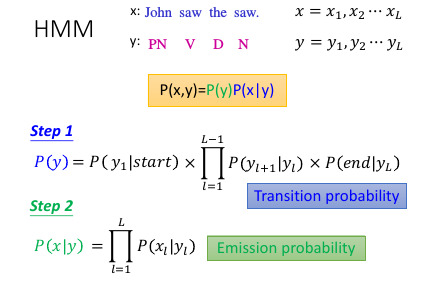
1.3.2 HMM-step 2

1.3.3 HMM-step1 and 2
 P(y) = P(PN|start)*P(V|PN)*P(D|V)*P(N|D)
这个公式,我一开始不明白,但是看了 HMM step1 的图形就理解了。
P(y) = P(PN|start)*P(V|PN)*P(D|V)*P(N|D)
这个公式,我一开始不明白,但是看了 HMM step1 的图形就理解了。
step 1: Transition Probability step 2: Emission Probability
1.3.4 HMM: 数数计算 P(x,y)
如何获取 P(V|PN), P('saw'|V) 通过训练数据获取收集一大堆句子,然后分别对所有单词标注其词性

有了数据之后,剩下的事情就是:数数

'start' and 'end' seems like '^' and '\(' ---> ^I love U\) 从左往右看: 先有 ^ 然后 I, U 然后 $: P(y1|start) = y1 occur in head / num of sentence P(end|yL) = yL occur in tail / num of sentence
这里的公式可以根据下图理解:P(s'|s) = count(s->s')/count(s)
+--------------------------------------------+
| |
| +-------------------+ |
| | | |
| +--------+-------+ | |
| | |.......| | |
| | |.......| s'| |
| | +---^---+-----------+ |
| | s | | |
| +------------+---+ |
| | Ω |
+---------------+----------------------------+
|
|
P(s'|s) = count(s->s')/count(s)
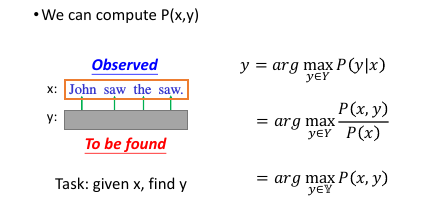
1.3.5 HMM-How to do POS tagging?
上面阐述了 MM 的大概原理,但是我们的任务是:给你一个新的句子,让你给出所有单词的词性。 Task: given x, find y
 因为我知道 P(x,y) 怎么算--数数即可算得。然后 y 又是一个语法范围内得组合,所以我就穷举 y 看哪个 P(x,y) 最大即可。
(又见‘穷举’)
因为我知道 P(x,y) 怎么算--数数即可算得。然后 y 又是一个语法范围内得组合,所以我就穷举 y 看哪个 P(x,y) 最大即可。
(又见‘穷举’)
1.3.6 HMM-Viterbi Algorithm
穷举是已件非常耗时得事情,我们可以使用:viterbi algo
 这里李老师没有具体得介绍 viterbi algo. 但是李老师推荐课后好好看看,并且说作业里面要用。总体来说,就是 viterbi algo 可以比较快速得给出哪一个 y 能让 P(x,y)最大
这里李老师没有具体得介绍 viterbi algo. 但是李老师推荐课后好好看看,并且说作业里面要用。总体来说,就是 viterbi algo 可以比较快速得给出哪一个 y 能让 P(x,y)最大
1.3.7 HMM-summary
HMM 其实也是 structure Learning 得一种方法:

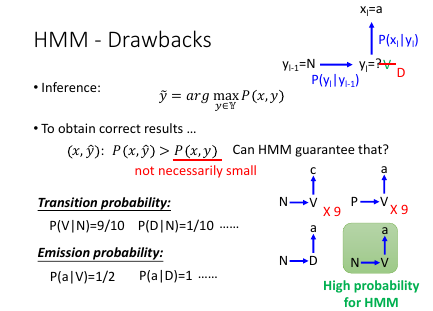
1.3.8 HMM-Drawbacks
 HMM 没法保证一个错误得 y 带入 P(x,y) 求得得概率一定是小得。
HMM 没法保证一个错误得 y 带入 P(x,y) 求得得概率一定是小得。
 如果给 yl-1 = N, yl=? , xl='a'
问:yl = ?
从概率上来看 N->V->a = 0.9*0.5 = 0.45
N->D->a = 0.1*1 = 0.1
所以结果应该是:yl = V
如果给 yl-1 = N, yl=? , xl='a'
问:yl = ?
从概率上来看 N->V->a = 0.9*0.5 = 0.45
N->D->a = 0.1*1 = 0.1
所以结果应该是:yl = V
但是这样做也许会有问题:如果训练数据中:
| N-V-c | 9 time | | P-V-a | 9 time | | N-D-a | 1 time |
这个符合刚才得概率,但是当我们再重新审视这个问题和样本数据时,会发现:样本中明明已经有了 N-D-a,而我们给出得估算确是:N-V-a,而 N-V-a 从来没有在样本中出现过。
HMM 会给出一些样本中从来没有出现过的 sequence HMM 的一大特色:他会‘脑补’他没有看过的东西
 这个未必是缺点:因为有可能只是你的样本数据收集的不够全面而已。所以,HMM 适合数据量较少的情况。
这个未必是缺点:因为有可能只是你的样本数据收集的不够全面而已。所以,HMM 适合数据量较少的情况。
当数据足够多时,再这么做就有点‘意淫’的味道了,过犹不及。所以当数据足够多时,HMM 的表现并不是很好。
>>> 为甚么 HMM 会出现这个缺点呢? --------------------------------------------------------- 因为 HMM 中,Transition Probability 和 Emission Probability 是分开 Model 的,HMM 假设他们是 independent ---------------------------------------------------------
CRF 可以用近乎相同的模型来纠正这个‘缺点’,他也假设 transition 和 emission 是相互独立的。
1.4 Conditional Random Field (CRF)
CRF 可以用近乎相同的模型来纠正这个‘缺点’,他也假设 transition 和 emission 是相互独立的。
 exp(w.φ(x,y)) 不能算是概率,因为他可以大于 1. 所以只能说,他跟几率是成正比的。但是这样,是不是就不知道真正的几率了?
exp(w.φ(x,y)) 不 care P(x,y)是多少,他在意的是 P(y|x) 是多少。
exp(w.φ(x,y)) 不能算是概率,因为他可以大于 1. 所以只能说,他跟几率是成正比的。但是这样,是不是就不知道真正的几率了?
exp(w.φ(x,y)) 不 care P(x,y)是多少,他在意的是 P(y|x) 是多少。
>>> 表示 P(x,y) ----------------------------------------- 因为 P(x,y) 与 exp(w.φ(x,y) 成正比:就可以写成 P(x,y) = exp(w.φ(x,y))/R ----------------------------------------- 蓝色公式,因为是 sum 所有可能的 y, 所以他跟 y 就没有关系了,也就是说他是一个关于 x 的函数,这里表示成:Z(x)
1.4.1 为甚么 P(x,y) 正比于 exp(w.φ)

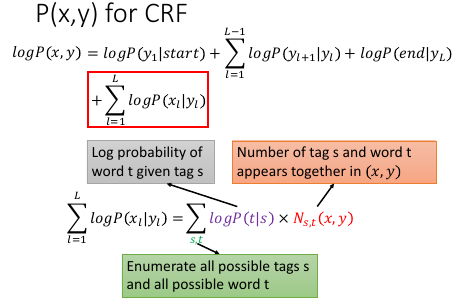 ΣlogP(t|s): 加总所有的 tag 和 word, 如果你有 10 个可能词性的 tag,世界上有 10000 个 word 的话就表示 s 有 10 个可能,而 t 有 10000 个不同的可能。那么 sum 就是 sum 10w 项。
Ns,t(x,y): 上面的每一项,word t 被标示成 tag s 这件事情,在(x,y)这个 pair 里面出现的次数。
ΣlogP(t|s): 加总所有的 tag 和 word, 如果你有 10 个可能词性的 tag,世界上有 10000 个 word 的话就表示 s 有 10 个可能,而 t 有 10000 个不同的可能。那么 sum 就是 sum 10w 项。
Ns,t(x,y): 上面的每一项,word t 被标示成 tag s 这件事情,在(x,y)这个 pair 里面出现的次数。


 因为 N..(x,y) 的部分是跟 x,y 有关的,而他是最类似 φ(x,y) 的但是这个 = 号是很有问题的,因为我们没有对 w 做任何限制,如果他大于
1, 在做 exponantial 回去的时候,得到的值是大于 1 的,这显然不能称其为概率,所以我们把 = 号改成 '正比' ,这样更方便用概率来解释而不影响其大于 1 的现实。
因为 N..(x,y) 的部分是跟 x,y 有关的,而他是最类似 φ(x,y) 的但是这个 = 号是很有问题的,因为我们没有对 w 做任何限制,如果他大于
1, 在做 exponantial 回去的时候,得到的值是大于 1 的,这显然不能称其为概率,所以我们把 = 号改成 '正比' ,这样更方便用概率来解释而不影响其大于 1 的现实。

1.4.2 Feature Vector 长什么样子呢?
包含两个部分:part1
 如果这个世界上有 10 个可能的词性 和 10000 个可能的单词,那么这个 vector 就有 10w 维度:每一个位,就是所有的词性跟所有的词汇的 pair.
可以看到他非常的 sparse
如果这个世界上有 10 个可能的词性 和 10000 个可能的单词,那么这个 vector 就有 10w 维度:每一个位,就是所有的词性跟所有的词汇的 pair.
可以看到他非常的 sparse
包含两个部分:part2

 每一个 tag 跟 tag ,总共 s*s 个 pair.
每一个 tag 跟 <start,end>,总共 s*2 个 pair.
所以 Part2 的维度是 s*s + s*2
每一个 tag 跟 tag ,总共 s*s 个 pair.
每一个 tag 跟 <start,end>,总共 s*2 个 pair.
所以 Part2 的维度是 s*s + s*2
[红色字体]: 因为 CRF 把他的几率描述成一个 weight 跟一个 feature vector 的内积。 所以,他比 HMM 多了一个厉害的地方就是:你可以按照现实需求自己定义 φ(x,y) ---定义自己的 feature vector. 所以 CRF 是一个相当灵活的模型。
Part1 Part2 叠在一齐就是 Feature Vector
1.4.3 CRF-Training Criterion
 这个部分参照下面的知乎回答做参考
这个部分参照下面的知乎回答做参考
LSTM 和 crf 是两个层面的东西。 crf 的核心概念,是计算序列全局的似然概率,其更像一个 loss 的选择方式。 与其相对应的应该是 cross entropy。 *crf 把一个序列当作一个整体来计算似然概率* ,而不是计算单点的似然概率。这样使得其在序列标注问题中效果比较好。即使现 在主流使用 LSTM 模型的,也会在 loss 层使用 crf,基本验证是更好的。 而与 LSTM 相对应的应 该是原来 crf 模型中特征层面的东东。 比如在传统的 crf 模型中,需要人工选择各种特征,但 是目前主流的解决方案中倾向于,embedding 层+bilstm 层,直接机器学习到特征。也就是 end-to-end 的思路。 作者:知乎用户 链接:https://www.zhihu.com/question/46688107/answer/136928113 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
这里这个'find w* maximizing object fn' 有点类似 cross-entropy. 只不过 cross-entropy 是 maximize 正确的那一个维度的概率,那是单点极大似然,而这里要做的是 maximize 那个正确的 sequence. 要让正确的 sequence 的几率的 log 值越大越好。
>>> 眼见为实,不见为虚 ------------------------------------------------------------------------ xn,y^n 是 training data 的点。 xn,y' 是 其他所有可能的 y 的取值,其中【大部分】可能都没有出现在 training data 里。 所以,我们要找到这样一个 w,他可以 maxlogP(y^n|xn) = max(logP(xn,y^n)) - min(logΣP(xn,y')) ===> find a w 最大化(我们观察到的样本对) and 最小化(大部分没有出现的样本对) ------------------------------------------------------------------------
如何找到这样的 w 呢,GA
1.4.4 CRF-Gradient Ascent: get w

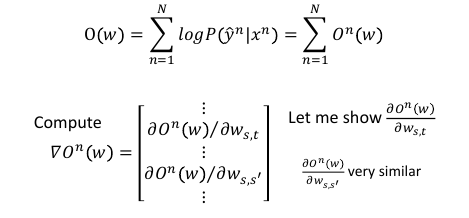
1.4.5 CRF-Training: get w
 s,t 在正确的 x,y 里面出现的次数 - 去和(任意一个 x,y pair 里面 s,t 出现的次数)这两项【黄、绿】是有一个 trade-off 的,绿色:如果 s,t 在正确的 training data 里出现很多,那对应的 weight: ws,t 就会增加黄色:任意一个 x,y pair 里面 s,t 出现的次数很多, 那对应的 weight: ws,t 就会减少
s,t 在正确的 x,y 里面出现的次数 - 去和(任意一个 x,y pair 里面 s,t 出现的次数)这两项【黄、绿】是有一个 trade-off 的,绿色:如果 s,t 在正确的 training data 里出现很多,那对应的 weight: ws,t 就会增加黄色:任意一个 x,y pair 里面 s,t 出现的次数很多, 那对应的 weight: ws,t 就会减少
黄色:Sum(所有可能的 y') 也可以用 Viterbi algo 来解决
 从刚才对 ws,t 偏微分的一个表达式 :Ns,t(xn, yn)
—> 现在对整个表达式求 Gradient 得到一个表达式:φ(xn,yn) 这个没问题:因为 feature vector φ: 就是由 'tags to words' and 'tags to tags'
形成的。s,t 可以概括这两种关系(回头看看 φ 向量的 2 parts 构成)
从刚才对 ws,t 偏微分的一个表达式 :Ns,t(xn, yn)
—> 现在对整个表达式求 Gradient 得到一个表达式:φ(xn,yn) 这个没问题:因为 feature vector φ: 就是由 'tags to words' and 'tags to tags'
形成的。s,t 可以概括这两种关系(回头看看 φ 向量的 2 parts 构成)
1.4.6 CRF-Inference: get w
 for all y max(w.φ(x,y)), 这个在 structured svm 中看到过,他也可以用
viterbi algo 求解。
for all y max(w.φ(x,y)), 这个在 structured svm 中看到过,他也可以用
viterbi algo 求解。
1.4.7 CRF v.s. HMM

>>> CRF vs HMM -------------- CRF 惩恶扬善 HMM 扬善 --------------
CRF 不但增加正确的 pair 的几率, 还减少任意其他 y 与 x 形成 pair 的几率 HMM 只 增加正确的 pair 的几率所以一反一正,比单单一反来的差距更大,而我们要做的就是要让正确的 pair 比其他的 pair 的几率更大,所以很明显 CRF 更容易做到这件事情。
 注意:
马尔科夫随机场跟贝叶斯网络一样都是产生式模型,条件随机场才是判别式模型。
注意:
马尔科夫随机场跟贝叶斯网络一样都是产生式模型,条件随机场才是判别式模型。
这里是用 mixed-order HMM 生成数据,然后用 HMM and CRF 来验证学习效果
transition probability 表达式是一个 mixed-order HMM ,他跟普通表达式的关系就是,如果 α = 1,那整个表达式就是普通的 HMM emission probability 也一样
>>> 何为 mixed-order ----------------------------------- 这个 order 就是 条件概率的先验条件的数目: αP(yi|yi-1) ---- 1-order αP(yi|yi-1,yi-2) ---- 2-order mixed-order, 就是存在多种先验条件的数目 -----------------------------------
mixed-order HMM 的 α 是用来调整这个 HMM 各个 order 之间的比重。
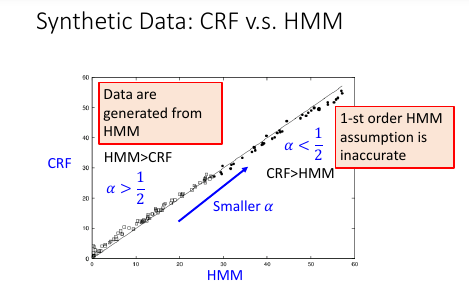 横轴,纵轴分别表示 HMM 和 CRF 犯错的百分比圆圈表示 α > 1/2, 实心圆表示 α < 1/2
横轴,纵轴分别表示 HMM 和 CRF 犯错的百分比圆圈表示 α > 1/2, 实心圆表示 α < 1/2
值得注意的是:
α > 1/2 时,mixed-order HMM 就更像 1-order HMM 所以 HMM 的效果更好;
α < 1/2 时,mixed-order HMM 就不像 1-order HMM, 此时数据对于 HMM CRF
是相对公平的,CRF 更好。
因为 CRF 会调整参数 fit 你的 data
1.4.8 CRF-Summary

*马尔科夫随机场跟贝叶斯网络一样都是产生式模型,条件随机场才是判别式模型。* 作者:赵孽 链接:https://www.zhihu.com/question/35866596/answer/74187736 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 来来来,这两天正好在复习 CRF,我从头给你说。。。 模型------首先什么是随机场呢,一组随机变量,他们样本空间一样,那么就是随机场。 当这些随机变量之间有依赖关系的时候,对我们来说才是有意义的。我们利用这些随机变量 之间的关系建模实际问题中的相关关系,实际问题中我们可能只知道这两个变量之间有相关 关系,但并不知道具体是多少,我们想知道这些依赖关系具体是什么样的,于是就把相关关 系【图画出来】,然后通过【实际数据训练】去把具体的相关关系训练出来嵌入到图里,然 后用得到的这个图去进行预测、去进行 reference 等很多事情。 那么为了简化某些为问题来说,也为了这个图画出来能用,我们会在画图的时候要遵循一些 假设和规则,比如 _马尔科夫独立性假设_ 。按照这个假设和规则来画图,画出来的图会满 足一系列方便的性质便于使用。马尔可夫独立性假设是说:对一个节点,在给定他所连接的 所有节点的前提下,他与外接是独立的。就是说如果你观测到了这个节点直接连接的那些节 点的值的话,那他跟那些不直接连接他的点就是独立的。形式上,我们是想把他设计成这个 样子的,边可以传递信息,点与点之间通过边相互影响,如果观测到一个节点的取值或者这 个节点的取值是常量,那么别的节点就无法通过这个节点来影响其他节点。所以对一个节点 来说,如果用来连接外界的所有节点都被锁住了,那他跟外界就无法传递信息,就独立了。 这比贝叶斯网络就直观多了,贝叶斯网络要判断两点之间独立还要看有没有 v-structure, 还要看边的指向。 呐,满足马尔可夫独立性的随机场,就叫马尔可夫随机场。 它不仅具有我刚才说的那些性质,除此之外,还等价于吉布斯分布。 这些边具体是如何建模的呢, 以什么形式记录这些概率信息的? 贝叶斯网络每一条边是一个 _条件概率分布_ ,P(X|Y),条件是父节点、结果是子节点。他 有一个问题,就是当我知道 A、B、C 三个变量之间有相关关系,但是不知道具体是谁依赖 谁,或者我不想先假设谁依赖谁,这个时候贝叶斯就画不出来图了。因为贝叶斯网络是通过 变量之间的条件分布来建模整个网络的,相关关系是通过依赖关系(条件分布)来表达的。 而马尔可夫随机场是这样,我不想知道这三个变量间到底是谁依赖谁、谁是条件谁是结果, 我只想用 _联合分布_ 直接表达这三个变量之间的关系。比如说两个变量 A、B,这两个变 量的联合分布是: | A, B | P(A, B) | |--------------+---------| | A = 0, B = 0 | 100 | | A = 0, B = 1 | 10 | | A = 1, B = 0 | 20 | | A = 1, B = 1 | 200 | 这个分布表示,这条边的功能是使它连接的两点(A 和 B)趋同,当 A = 0 的时候 B 更可 能等于 0 不太可能等于 1,当 A = 1 的时候 B 更可能等于 1 不太可能等于 0。这样一来 你知道了三个变量之间的联合分布,那他们两两之间的条件分布自然而然就在里面。这样出 来的图是等价于吉布斯分布的,就是说,你可以只在每个最大子团上定义一个联合分布(而 不需要对每个边定义一个联合分布),整个图的联合概率分布就是这些最大子团的联合概率 分布的乘积。 当然这里最大子团的联合概率并不是标准的联合概率形式,是没归一化的联合概率,叫 factor(因子),整个图的联合概率乘完之后下面再除一个归一化因子和就归一化了,最终 是一个联合概率,每个子团记载的都是因子,是没归一化的概率,严格大于零,可以大于一。 但关键是 _依赖关系、这些相关关系已经 encode 在里面了_ 。这是马尔科夫随机场。 条件随机场是指这个图里面一些点我已经观测到了,求,在我观测到这些点的前提下,整张 图的分布是怎样的。就是 given 观测点,你去 map inference 也好你去做之类的事情,你 可能不求具体的分布式什么。 这里还要注意的是, *马尔科夫随机场跟贝叶斯网络一样都是产生式模型,条件随机场才是判别式模型。* 这是条件随机场,NER(命名实体识别)这个任务用到的是线性链条件随机场。线性链条件 随机场的形式是这样的,观测点是你要标注的这些词本身和他们对应的特征,例如说词性是 不是专有名词、语义角色是不是主语之类的。隐节点,是这些词的标签,比如说是不是人名 结尾,是不是地名的开头这样。这些隐节点(就是这些标签),依次排开,相邻的节点中间 有条边,跨节点没有边(线性链、二阶)。然后所有观测节点(特征)同时作用于所有这些 隐节点(标签)。至于观测节点之间有没有依赖关系,这些已经不重要了,因为他们已经被 观测到了,是固定的。这是线性链条件随机场的形式。 呐,这些特征是怎么表达的呢? 是这样,他有两种特征, 一种是转移特征,就是涉及到两个 状态之间的特征。 另一种就是简单的状态特征,就是只涉及到当前状态的特征。 特征表达形式比较简单,就是你是否满足我特征所说的这个配置,是就是 1,不是就是 0。比 如说,上一个状态是地名的中间,且当前词是'国'(假设他把中国分词拆成两个了),且当 前词的词性是专有名词、且上一个词的词性也是专有名词,如果满足这个配置、输出就是 1、 不满足就输出 0。然后这些特征每个都有一个权重,我们最后要学的就是这些权重。特征跟 权重乘起来再求和,外面在套个 exp,出来就是这个 factor 的形式。这是一个典型的对数 线性模型的表达方式。这种表达方式非常常见,有很多好处,比如为什么要套一个 exp 呢? 一方面,要保证每一个 factor 是正的,factor 可以大于一也可以不归一化,但一定要是 正的。另一方面,我们最后要通过最大似然函数优化的,似然值是这些 factor 的累乘,对 每一个最大子团累乘。这么多项相乘没有人直接去优化的,都是取 log 变成对数似然,然 后这些累乘变成累加了嘛,然后优化这个累加。无论是算梯度用梯度下降,还是另导数为零 求解析解都很方便了(这个表达形态下的目标函数是凸的)。你套上 exp 之后,再取对数, 那么每个因子就变成一堆特征乘权重的累积,然后整个对数似然就是三级累积,对每个样本、 每个团、每个特征累积。这个形式就很有利了,你是求导还是求梯度还是怎样,你面对的就 是一堆项的和,每个和是一个 1 或者一个 0 乘以一个权重。当然后面还要减一个 log(Z), 不过对于 map inference 来说,给定 Z 之后 log(Z)是常量,优化可以不带这一项。推 断------线性链的条件随机场跟线性链的隐马尔科夫模型一样,一般推断用的都是维特比算 法。这个算法是一个最简单的动态规划。首先我们推断的目标是给定一个 X,找到使 P(Y|X)最大的那个 Y 嘛。然后这个 Z(X),一个 X 就对应一个 Z,所以 X 固定的话这个项 是常量,优化跟他没关系(Y 的取值不影响 Z)。然后 exp 也是单调递增的,也不带他, 直接优化 exp 里面。所以最后优化目标就变成了里面那个线性和的形式,就是对每个位置 的每个特征加权求和。比如说两个状态的话,它对应的概率就是从开始转移到第一个状态的 概率加上从第一个转移到第二个状态的概率,这里概率是只 exp 里面的加权和。那么这种 关系下就可以用维特比了,首先你算出第一个状态取每个标签的概率,然后你再计算到第二 个状态取每个标签得概率的最大值,这个最大值是指从状态一哪个标签转移到这个标签的概 率最大,值是多少,并且记住这个转移(也就是上一个标签是啥)。然后你再计算第三个取 哪个标签概率最大,取最大的话上一个标签应该是哪个。以此类推。整条链计算完之后,你 就知道最后一个词去哪个标签最可能,以及去这个标签的话上一个状态的标签是什么、取上 一个标签的话上上个状态的标签是什么,酱。这里我说的概率都是 exp 里面的加权和,因 为两个概率相乘其实就对应着两个加权和相加,其他部分都没有变。 学习------这是一个典型的无条件优化问题,基本上所有我知道的优化方法都是优化似然函 数。典型的就是梯度下降及其升级版(牛顿、拟牛顿、BFGS、L-BFGS),这里版本最高的就 是 L-BFGS 了吧,所以一般都用 L-BFGS。除此之外 EM 算法也可以优化这个问题。
1.5 Structured Perceptron/SVM

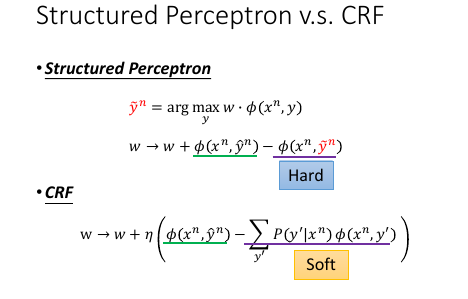 Hard: Structure Perceptron 是减去【几率最大的那个φ】
Soft: CRF 是减去【所有φ的带权平均】
Hard: Structure Perceptron 是减去【几率最大的那个φ】
Soft: CRF 是减去【所有φ的带权平均】
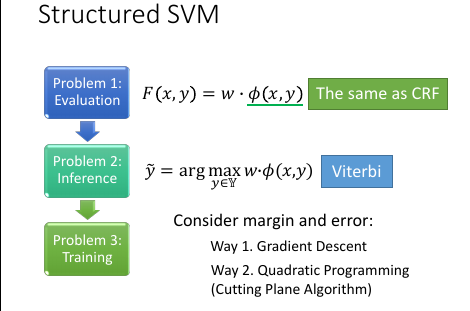
 这里的例子是把 Δ 定义成误差率
这里的例子是把 Δ 定义成误差率
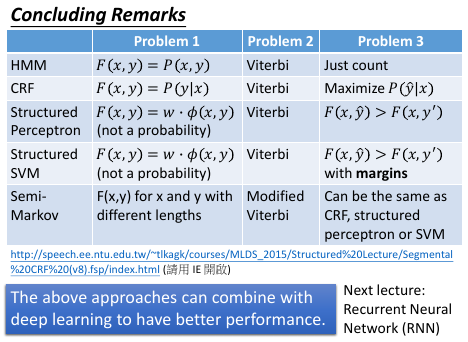
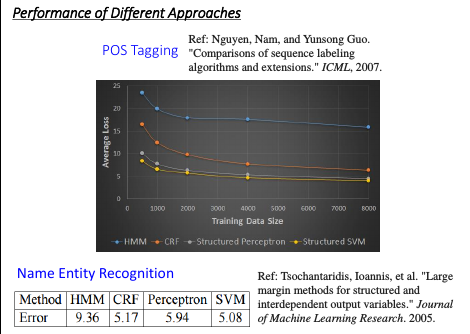 HMM > Perceptron > CRF > SVM
HMM > Perceptron > CRF > SVM
1.6 How about RNN
|-------------------------------------+--------------------------------------| | RNN,LSTM | HMM,CRF,Structured Perceptron/SVM | |-------------------------------------+--------------------------------------| | • Unidirectional RNN dose not | • Using viterbi, so consider the | | consider the whole sequence | whole sequence ✓ | | • Can learned by RNN but too slow | • Can explicityly consider the label | | | dependency ✓ | | • Cost and error not always related | • Cost is the upper bound of error ✓ | | • Can be Deep ✓✓✓✓ | | |-------------------------------------+--------------------------------------|
HMM 梯队的 1) 由于使用的是 viterbi 算法,他会穷举每一种可能的序列,从中挑出最好的 RNN 梯队的 1) 如果是单方向的 RNN,他只会根据之前看的到 sequence 做输出,并没有考虑整个 sequence HMM 梯队的 2) 可以把‘某两个绝对不能同时出现’这种【标签依赖】条件加入到 viterbi 算法中 比如中文都是【声母接韵母】,决对不会出现【声母接声母】。在做 viterbi 算法的时候 就可以只穷举那些符合条件的,filter 掉那些【声母接声母】的。
1.6.1 Integrated Together
1.6.2 [RNN/LSTM] + [HMM/CRF/SP/SSVM]
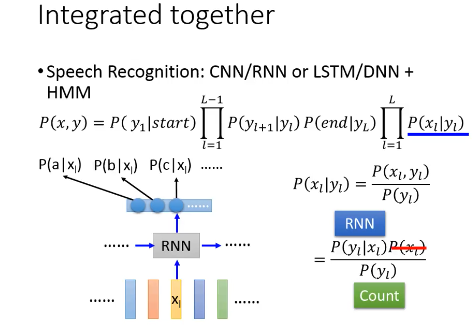 RNN 的输出是 P(a|x1)P(b|x1)P(c|x1)…
而根据前面的想法,我想把 RNN 接到 P(xl|yl) 上去,所以需要做转换
P(xl|yl) = P(xl,yl)/P(yl) = P(yl|xl)P(xl)/P(yl)
其中
P(yl|xl) 交给 RNN.
P(xl) 直接忽略,因为做 HMM 的时候是 given xl 看哪个 y 几率最大换言之,xl 是给定的,不管他是多少,都不影响 y 是哪个。
P(yl) 通过 training data 数数得到
RNN 的输出是 P(a|x1)P(b|x1)P(c|x1)…
而根据前面的想法,我想把 RNN 接到 P(xl|yl) 上去,所以需要做转换
P(xl|yl) = P(xl,yl)/P(yl) = P(yl|xl)P(xl)/P(yl)
其中
P(yl|xl) 交给 RNN.
P(xl) 直接忽略,因为做 HMM 的时候是 given xl 看哪个 y 几率最大换言之,xl 是给定的,不管他是多少,都不影响 y 是哪个。
P(yl) 通过 training data 数数得到
1.6.3 [Bi-directional RNN/LSTM] + [HMM/CRF/SP/SSVM]
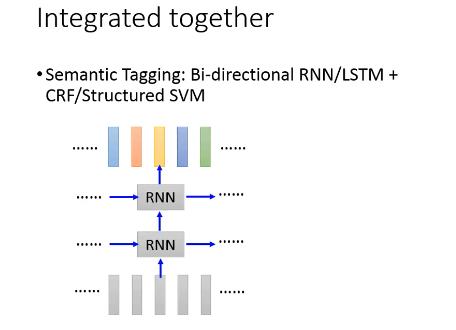
1.7 4 种模型总结