lec-29 Language Modeling by RNN
Table of Contents
- 1. Language Modeling by RNN
1 Language Modeling by RNN
[作业 1]
1.1 what is LM and its Application

- language model 是什么?估计一个句子(一串单词组成)的出现概率:P(w1,w2,w3,…,wn)
- 有什么应用?
- 语音辨识中 发音相同但是内容不同 就需要概率来选择
- 句子生成中 中多合格的句子中选择语法最合理的, 也需要概率
- chat-bot 中机器从眾多句子中选择一个,也需要概率
1.2 N-gram: LM 传统做法(不用 NN)
核心公式是:
P(w1,w2,w3,...,wn) = P(w1|start)P(w2|w1)P(w3|w2)...
计算 P(wn|wn-1)方法是:查 dataset 中单词数目

1. 有可能你要估计概率的句子,根本没有在 dataset 中出现过,怎么办? 把整个句子拆开,拆成: 2-gram: P(w3|w2) or 3-gram: P(w3|w2,w1) or 2. 2-gram 就是只考虑某个单词跟前一个单词出现的概率: P(w2|w1) P(wn|wn-1) 3. 在统计每个 gram 出现的概率,相乘即可
1.3 NN-based LM
核心公式是: P(w1,w2,w3,...,wn) = P(w1|start)P(w2|w1)P(w3|w2)... 计算 P(wn|wn-1)方法是: 通过训练 NN 来来预测下一个单词的概率, input: one-hot(wn-1), output: P(w2|w1)
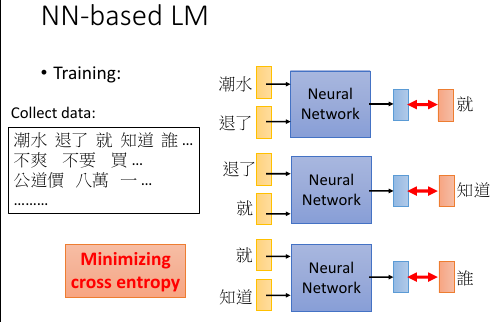
- collect data
- learn 一个 NN, predict next word
1. 与传统的【查单词数算概率】的方法计算 P(w2|w1) 概率的区别
采用一个 NN 来输出 P(w2|w1)
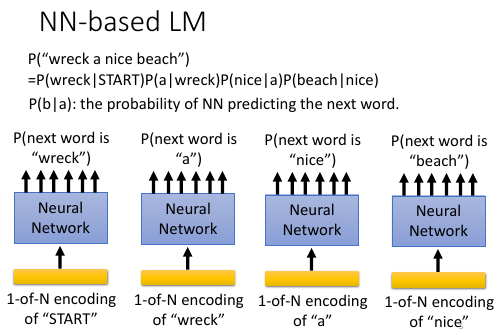
2. NN-based LM 采用一个 NN 来预测下列内容:
1) 收集一堆 data, 训练一个 NN 用来预测【下一个单词】
2) NN.input = one-hot encoding of a word
NN.output = 十万维向量(词典有多长向量就多长),向量每一位都是概率值
eg. 对于 P(w2|w1) 来说
input w1, output w2 的概率
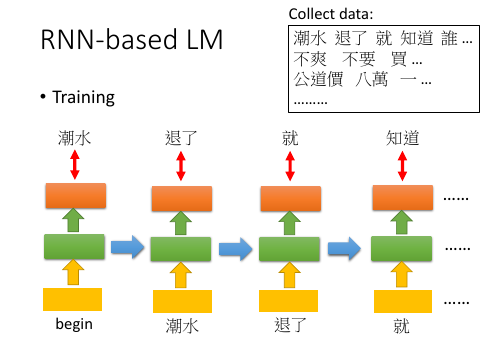
1.4 RNN-based LM
核心公式是: P(w1,w2,w3,...,wn) = P(w1)P(w2|w1)P(w3|w2,w1)P(w4|w3,w2,w1)... 计算 P(wn|wn-1,wn-2,...)方法是: 通过训练 RNN 来来预测下一个单词的概率, - input: one-hot(wn-1), result of last RNN hn-1 - output: P(wn|wn-1,wn-2,...)
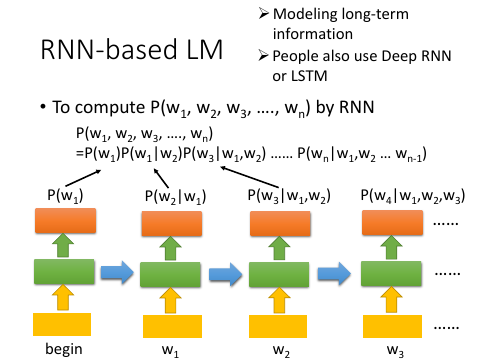
1. 与 NN-based model 差别
NN-based model 只看了【前一个单词】,就预测下一个单词的出现概率,相当于
P(w2|w1), P(w3|w2), P(w4|w3)
RNN-based model 是看了【前面出现的所有单词】,才预测下一个:
P(w2|w1), P(w3|w2,w1), P(w4|w3,w2,w1)
1.5 为甚么 RNN-based LM 更好
1.5.1 数据不足对传统方法的冲击及应对方法

- 传统方法的弊端:由于传统方法计算 P(w2|w1) 是通过【查单词数】的方法来估算,所以这对数据集要求很高。
- 什么是 data sparsity: 否则就会出现很多概率为 0 的 P(wn|wn-1) 这种现象叫做:data sparsity
- 怎么解决?language model smoothing 永远不要给 P(wn|wn-1) = 0. 凡是 data set 中没有的,都给定一个概率 0.0001
1.5.2 比 smoothing 更好的方法:matrix factorization
>>> 公共技巧:出现 sparsity 想到什么
出现 sparsity 想到用 matrix factorization 来填充 0 点。
1.5.3 matrix factorization 优点 1: 估算 0 值

- history vocabulary 必须是维度相同的向量,因为要计算两者的内积
- v 和 h 都是向量,其中 history 是行, vocabulary 是列。而表格中的值都是 P(vocabulary|history), 来自于通过【查单词数】的方法得到的值。
- 由于数据集可能不够大,所以有很多值是没有统计到的 — 0.
- 我们仅仅使用【有值的数据】通过 minimize loss-fn 得到所有的 v 向量和 h 向量。使得 v • h ≈ n
- 得到 v 和 h 之后就可以通过 v•h 来估算那些原来值为 0 的那些格子。
1.5.4 matrix factorization 优点 2: 保留相似单词的推理

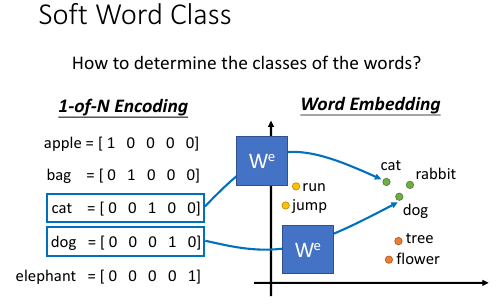
- 这种方法的好处:保留部分 vocabulary 之间的相似性的计算结果: 如果 cat 能 jump, cat 和 dog 很像,那么 dog 也能 jump. cat 和 dog 之间的相似性,被保留并被【推理】
- 要求:每一列的概率和应该为 1 P(all v| dog) = 1
1.5.5 用 NN 来实现 matrix factorization
Matrix Factorization 是可以写成一个 NN . matrix factorization 写成 NN 之后,该如何满足【每一列的概率和为 1】的要求。
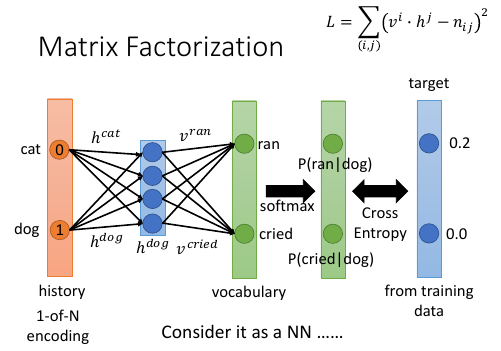 考虑用 softmax 来满足【每一列的概率和为 1】的要求。
考虑用 softmax 来满足【每一列的概率和为 1】的要求。
- input layer 是 one-hot encoding 编码的 history。既然是 history 就跟 P(w2|w1)的‘|’后面那个有关,如果是 2-gram, 那么这个 one-hot 向量的长度就是 N= len(vocabulary). 如果是 3-gram, 那么这个 one-hot 向量的长度就是 N*N. 这一层相当于对某个 history 进行选择。
- 获得这个 history 的向量:被选中的那个 history(eg. dog) 才会通过 hdog 权重产生 hiden-layer: hdog 向量
- hdog layer(就是 hdog 向量) 会与一个矩阵做内积(这个矩阵就是所有的 v 向量组成的). 输出的就是一个数值,但这个数值可能不是概率。
- 所以 step 3) 的结果需要经过一个 softmax 转换,转换之后的值就可以看做是 P(ran|dog) P(cried|dog)
- 把这个跟训练集数据做 minimize cross-entropy
>>> 为甚么要使用 NN 来实现这个 matrix factorization?
因为 NN 版的 matrix factorization 参数更少 : …………传统方法……………….. num of history = |h|; num of vocabulary = |v|; 2-gram, num of P(v|h) = |v|*|h| 3-gram, num of P(v|h) = |v|*|h|*|h| …………NN 实现……………….. [qqq 这里没听懂] 可以手动指定 h 向量和 v 向量的维度, 所以参数更少
1.5.6 用 RNN 来实现 matrix factorization
为甚么用 RNN 来实现,因为参数比 NN 还少。
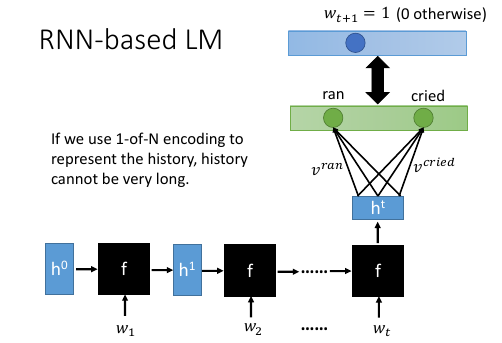
如果 history 很长,那么 NN 和传统方法都很无力如果要考虑前 t 个词汇,那么有多少种可能的组合呢?需要考虑词汇顺序
|v|^t 如果 vocabulary = 10w:
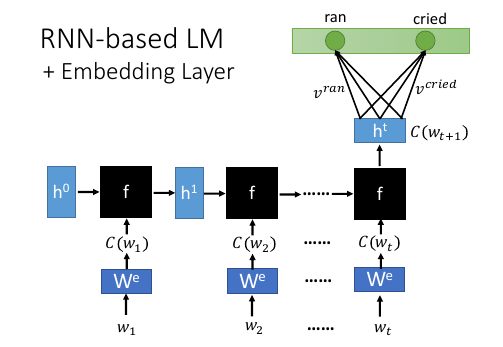
传统方法传统方法需要计算 10w * 10wt 个 P(v|h)NN-basedone-hot encoding 是 10wt 维度- [qqq]RNN-based model 使用最后一个 RNN 的 输出作为整个序列(history)的代表。传统方法和 NN-based 方法对于 history 的表示 跟 |v| 和 |h| 都有关而 RNN 中 P(wt+1|wt,wt-1,wt-2….,w1) -> P(wt+1|ht) '|' 后面那一串向量就只用一个 ht 向量表示剩下的绿色部分跟 hdog vector 后面的 softmax 等等一样。这个参数就节省太多了。
1.6 Class-based LM
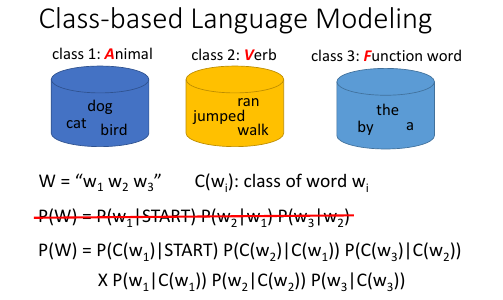
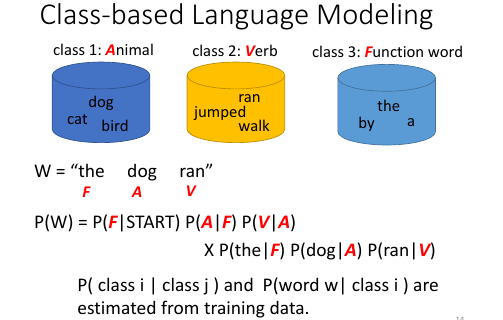

1.7 Soft Word Class
1.8 RNN-based LM + Embedding Layer
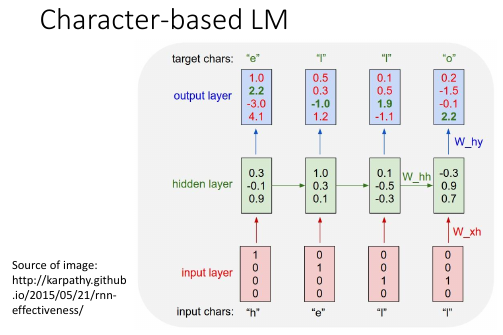
1.9 Character-based LM
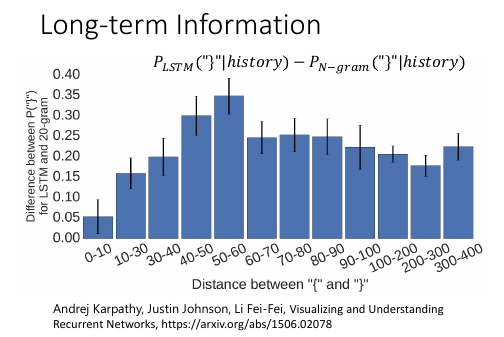
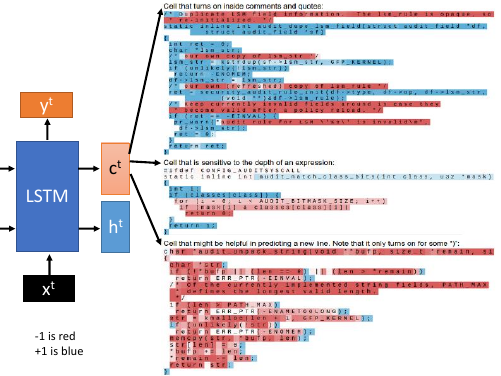
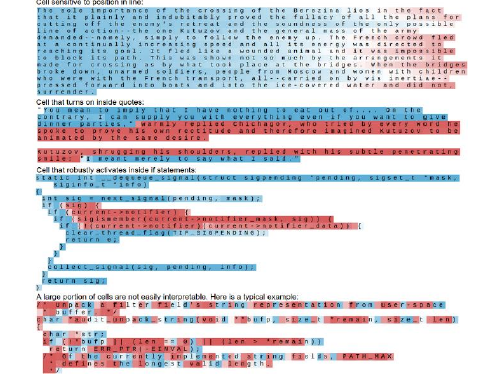
1.10 CNN for ML
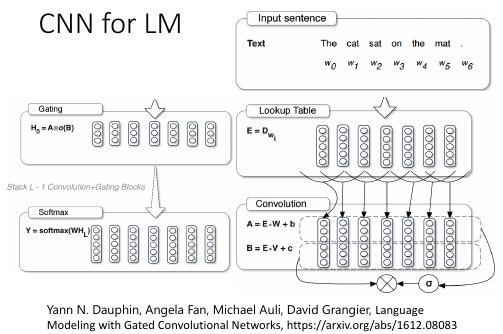
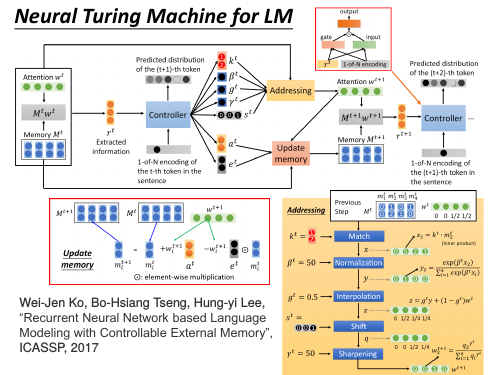
1.11 Neural Turing Machine for LM
1.12 Reference
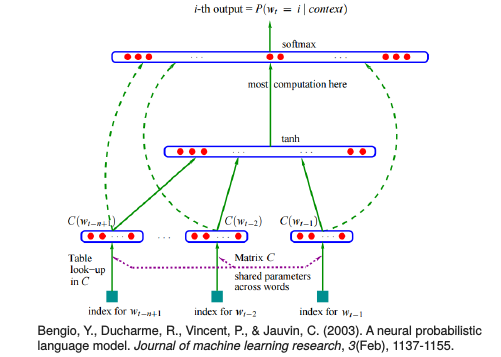
For Large Output Layer • Factorization of the Output Layer • Mikolov Tomáš: Statistical Language Models based on Neural Networks. PhD thesis, Brno University of Technology, 2012. (chapter 3.4.2) • http://speech.ee.ntu.edu.tw/~tlkagk/courses/MLDS_2015/NN Lecture/ RNNLM.ecm.mp4/index.html •••Noise Contrastive Estimation (NCE) • X. Chen, X. Liu, M. J. F. Gales and P. C. Woodland, "Recurrent neural network language model training with noise contrastive estimation for speech recognition,“ ICASSP, 2015 • B. Zoph , A. Vaswani, J. May, and K. Knight, “Simple, Fast Noise-Contrastive Estimation for Large RNN Vocabularies” , NAACL, 2016 Hierarachical Softmax • F Morin, Y Bengio, “Hierarchical Probabilistic Neural Network Language Model”, Aistats, 2005 Blog••posts: http://sebastianruder.com/word-embeddings-softmax/index.html http://cpmarkchang.logdown.com/posts/276263--hierarchical- probabilistic-neural-networks-neural-network-language-model
1.12.1 To learn more
• M. Sundermeyer, H. Ney and R. Schlüter, From Feedforward to Recurrent LSTM Neural Networks for Language Modeling, in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 23, no. 3, pp. 517-529, 2015. • Kazuki Irie, Zoltan Tuske, Tamer Alkhouli, Ralf Schluter, Hermann Ney, “LSTM, GRU, Highway and a Bit of Attention: An Empirical Overview for Language Modeling in Speech Recognition”, Interspeech, 2016 • Ke Tran, Arianna Bisazza, Christof Monz, Recurrent Memory Networks for Language Modeling, NAACL, 2016 • Jianpeng Cheng, Li Dong and Mirella Lapata, Long Short- Term Memory-Networks for Machine Reading, arXiv preprint, 2016